基础
马尔科夫决策(MDP)
在随机过程中某时刻$t$的状态用$S_t$表示,所以可能的状态组成了状态空间$S$。
如果已知历史的状态信息即$(S_1,…,S_t)$,那么下一个时刻状态为$S_{t+1}$的概率为$P(S_{t+1}\mid S_1,…,S_t)$
当且仅当某时刻的状态只取决于上一时刻的状态时,一个随机过程被称为具有马尔可夫性质
$$ P(S_{t+1}\mid S_t)=P(S_{t+1}\mid S_1,…,S_t) $$ 也就是说当前状态是未来的充分统计量,即下一个状态只取决于当前状态,而不会受到过去状态的影响。
注意:
虽然$t+1$时刻的状态只与$t$时刻的状态有关,但是$t$时刻的状态其实包含了$t-1$时刻的状态的信息,通过这种链式的关系,历史的信息被传递到了现在。
Markov process
通常用两元组$<S,P>$描述一个马尔科夫过程,其中$S$是有限状态集合,$P$是状态转移矩阵
矩阵$P$中第$i$行第$j$列$P(s_j|s_i)$表示状态$s_i$转移到状态$s_j$的概率,从某个状态出发,到达其他状态的概率和必须为1,即状态转移矩阵的每一行的和为1。
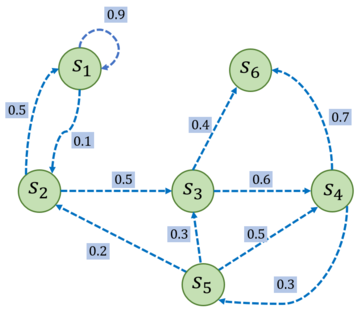
给定一个马尔可夫过程,我们就可以从某个状态出发,根据它的状态转移矩阵生成一个状态序列(episode),这个步骤也被叫做采样(sampling)。
Markov reward process(MRP)
一个马尔科夫奖励过程由$\langle \mathcal{S},\mathcal{P},r,\gamma \rangle$
- $\mathcal{S}$ 是有限状态的集合。
- $\mathcal{P}$ 是状态转移矩阵。
- $r$是奖励函数,某个状态$s$的奖励$r(s)$指转移到该状态时可以获得奖励的期望。
- $\gamma$ 是折扣因子,$\gamma$的取值为$[0,1)$ 。引入折扣因子的理由为远期利益具有一定不确定性,有时我们更希望能够尽快获得一些奖励,所以我们需要对远期利益打一些折扣。接近 1 的 $\gamma$ 更关注长期的累计奖励,接近0的$\gamma$ 更考虑短期奖励。
奖励函数的本质:向智能体传达目标(MDP)
强化学习的标准交互过程如下:每个时刻,智能体根据根据其 策略(policy),在当前所处 状态(state) 选择一个 动作(action),环境(environment) 对这些动作做出相应的相应的响应,转移到新状态,同时产生一个 奖励信号 (reward),这通常是一个数值,奖励的折扣累加和称为 收益/回报 (return),是智能体在动作选择过程中想要最大化的目标
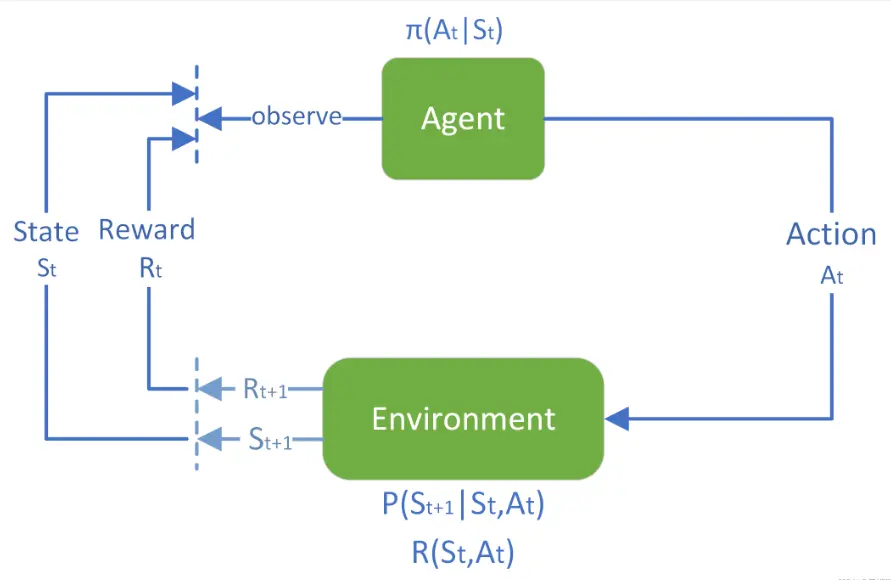
- “奖励 & 收益” 其实是智能体目标的一种形式化、数值化的表征。可以把这种想法非正式地表述为 “收益假设”
- 收益是通过奖励信号计算的,而奖励函数是我们提供的,奖励函数起到了人与算法沟通的桥梁作用
- 需要注意的是,智能体只会学习如何最大化收益,如果想让它完成某些指定任务,就必须保证我们设计的奖励函数可以使得智能体最大化收益的同时也能实现我们的目标
回报
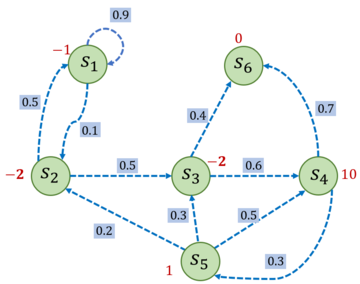
在一个马尔可夫奖励过程中,从第$t$时刻状态$S_t$开始,直到终止状态时,所有奖励的衰减之和称为回报(Return)
假设设置$\gamma =0.5$
 $$
G_t=R_t+\gamma R_{t+1}+\gamma^2 R_{t+2}+\cdots=\sum_{k=0}^{\infty} \gamma^k R_{t+k}
$$
假设路径为1,2,3,6
$$
G_t=R_t+\gamma R_{t+1}+\gamma^2 R_{t+2}+\cdots=\sum_{k=0}^{\infty} \gamma^k R_{t+k}
$$
假设路径为1,2,3,6
import numpy as np
np.random.seed(0)
#概率转移矩阵
P=[
[0.9,0.1,0.0,0.0,0.0,0.0],
[0.5,0.0,0.5,0.0,0.0,0.0],
[0.0,0.0,0.0,0.6,0.0,0.4],
[0.0,0.0,0.0,0.0,0.3,0.7],
[0.0,0.2,0.3,0.5,0.0,0.0],
[0.0,0.0,0.0,0.6,0.0,1.0],
]
P=np.array(P)
rewards=[-1,-2,-2,10,1,0]
gamma=0.5
def compute_chain_reward(start_index,chain,gamma):
reward=0
for i in range(len(chain)):
reward=gamma*reward+rewards[chain[i]-1]
return reward
chain=[1,2,3,6]
start_index=0
reward=compute_chain_reward(start_index,chain,gamma)
print(reward)
状态价值函数
一个状态的期望回报(即从这个状态出发的未来累积奖励的期望)->价值
即其状态价值函数$V_{\pi}(s)$就等于转移到每个通路上的概率(由策略决定)乘以每条路上得到的回报即
$V(s)=\mathbb{E}\left[G_t \mid S_t=s\right]$
展开为: $$ \begin{align} V(s) &=\mathbb{E}[G_t \mid S_t=s] \ &=\mathbb{E}[R_t+\gamma R_{t+1}+\gamma^2 R_{t+2}+…\mid S_t=s]\ &=\mathbb{E}[R_t+\gamma(R_{t+1}+\gamma R_{t+2})+… \mid S_t=s]\ &=\mathbb{E}[R_t+\gamma G_{t+1}\mid S_t=s]\ &=\mathbb{E}[R_t+\gamma V(S_{t+1})\mid S_t=s]\ \end{align} $$ 一方面,即时奖励的期望正是奖励函数的输出,即:
$\mathbb{E}\left[R_t \mid S_t=s\right]=r(s)$
另一方面,等式中剩余部分 $\mathbb{E}\left[\gamma V\left(S_{t+1}\right) \mid S_t=s\right]$ 可以根据从状态$s$出发的转移概率得到,即可以得到 $$ V(s)=r(s)+\gamma\sum_{s^{\prime} \in S }{p(s^{\prime} \mid s)V(s^\prime)} $$ 上式就是马尔可夫奖励过程中非常有名的贝尔曼方程 (Bellman equation),对每一个状态都成立。
上式就是马尔可夫奖励过程中非常有名的贝尔曼方程 (Bellman equation),对每一个状态都成立。
若一个马尔可夫奖励过程一共有 $n$ 个状 态,即 $\mathcal{S}=\left{s_1, s_2, \ldots, s_n\right}$ ,我们将所有状态的价值表示成一个列向量 $\mathcal{V}=\left[V\left(s_1\right), V\left(s_2\right), \ldots, V\left(s_n\right)\right]^T$ ,同理,将奖励函数写成一个列向量 $\mathcal{R}=\left[r\left(s_1\right), r\left(s_2\right), \ldots, r\left(s_n\right)\right]^T$ 。于是我们可以将贝尔曼方程写成矩阵的形式: $$ \begin{gathered} \mathcal{V}=\mathcal{R}+\gamma \mathcal{P} \mathcal{V} \ {\left[\begin{array}{c} V\left(s_1\right) \ V\left(s_2\right) \ \ldots \ V\left(s_n\right) \end{array}\right]=\left[\begin{array}{c} r\left(s_1\right) \ r\left(s_2\right) \ \ldots \ r\left(s_n\right) \end{array}\right]+\gamma\left[\begin{array}{cccc} P\left(s_1 \mid s_1\right) & p\left(s_2 \mid s_1\right) & \ldots & P\left(s_n \mid s_1\right) \ P\left(s_1 \mid s_2\right) & P\left(s_2 \mid s_2\right) & \ldots & P\left(s_n \mid s_2\right) \ \ldots & & & \ P\left(s_1 \mid s_n\right) & P\left(s_2 \mid s_n\right) & \ldots & P\left(s_n \mid s_n\right) \end{array}\right]\left[\begin{array}{c} V\left(s_1\right) \ V\left(s_2\right) \ \ldots \ V\left(s_n\right) \end{array}\right]} \end{gathered} $$ 我们可以直接根据矩阵运算求解,得到以下解析解: $$ \begin{aligned} \mathcal{V} & =\mathcal{R}+\gamma \mathcal{P} \mathcal{V} \ (I-\gamma \mathcal{P}) \mathcal{V} & =\mathcal{R} \ \mathcal{V} & =(I-\gamma \mathcal{P})^{-1} \mathcal{R} \end{aligned} $$
def compute_state_value(P,rewards,gamma,states_num):
rewards=np.array(rewards).reshape((-1,1))
value=np.dot(np.linalg.inv(np.eye(states_num)-gamma*P),rewards)
return value
state_value=compute_state_value(P,rewards,gamma,6)
print(state_value)
动作价值函数
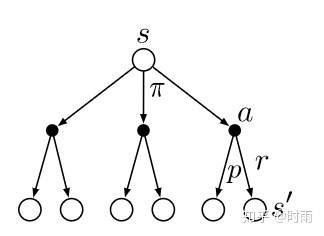
我们用 $Q^\pi(s, a)$ 表示在 MDP 遵循策略 $\pi$ 时,对当前状态 $s$ 执行动作 $a$ 得到的期望回报: $$ Q^\pi(s, a)=\mathbb{E}\pi\left[G_t \mid S_t=s, A_t=a\right] $$ 状态价值函数和动作价值函数之间的关系:在使用策略 $\pi$ 中,状态 $s$ 的价值等于在该状态下基于策略 $\pi$ 采取所有动作的概率与相应的价值相乘 再求和的结果: $$ V^\pi(s)=\sum{a \in A} \pi(a \mid s) Q^\pi(s, a) $$ 使用策略 $\pi$ 时,状态 $s$ 下采取动作 $a$ 的价值等于即时奖励加上经过衰减后的所有可能的下一个状态的状态转移概率与相应的价值的乘积: $$ Q^\pi(s, a)=r(s, a)+\gamma \sum_{s^{\prime} \in S} P\left(s^{\prime} \mid s, a\right) V^\pi\left(s^{\prime}\right) $$
贝尔曼期望方程
$$ \begin{aligned} V^\pi(s) & =\mathbb{E}\pi\left[R_t+\gamma V^\pi\left(S{t+1}\right) \mid S_t=s\right] \ & =\sum_{a \in A} \pi(a \mid s)\left(r(s, a)+\gamma \sum_{s^{\prime} \in S} p\left(s^{\prime} \mid s, a\right) V^\pi\left(s^{\prime}\right)\right) \ \end{aligned} $$
$$ \begin{aligned} Q^\pi(s, a) & =\mathbb{E}\pi\left[R_t+\gamma Q^\pi\left(S{t+1}, A_{t+1}\right) \mid S_t=s, A_t=a\right] \ & =r(s, a)+\gamma \sum_{s^{\prime} \in S} p\left(s^{\prime} \mid s, a\right) \sum_{a^{\prime} \in A} \pi\left(a^{\prime} \mid s^{\prime}\right) Q^\pi\left(s^{\prime}, a^{\prime}\right) \end{aligned} $$
MDP
$\langle \mathcal{S},\mathcal{A},P,r,\gamma \rangle$
-
$\mathcal{S}$是状态集合
-
$\mathcal{A}$ 是动作的集合;
-
$\gamma$ 是折扣因子;
-
$r(s, a)$ 是奖励函数,此时奖励可以同时取决于状态 $s$ 和动作 $a$ ,在奖励函数 只取决于状态 $s$ 时,则退化为 $r(s)$ ;
-
$P\left(s^{\prime} \mid s, a\right)$ 是状态转移函数,表示在状态 $s$ 执行动作 $a$ 之后到达状态 $s^{\prime}$ 的概 率。
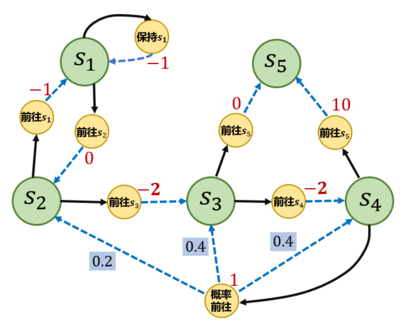
#mdp过程
state=['s1','s2','s3','s4','s5','s6']
action=['s1->s1','s1->s2','s2->s1','s2->s3','s3->s4','s3->s5','s4->s5','s4->s3','s4->s4','s4->s2']
#状态转移概率
P={
's1->s1':1.0,
's1->s2':1.0,
's2->s1':1.0,
's2->s3':1.0,
's3->s4':1.0,
's3->s5':1.0,
's4->s5':1.0,
's4->s3':0.2,
's4->s4':0.4,
's4->s2':0.2,
}
#奖励函数
rewards={
's1->s1':-1.0,
's1->s2':0,
's2->s1':-1.0,
's2->s3':-2.0,
's3->s4':-2.0,
's3->s5':0,
's4->s5':10,
's4->s3':1.0,
's4->s4':1.0,
's4->s2':1.0,
}
gamma=0.5
MDP=(state,action,P,rewards,gamma)
#策略1 随机策略
Pi_1={
's1->s1':0.5,
's1->s2':0.5,
's2->s1':0.5,
's2->s3':0.5,
's3->s4':0.5,
's3->s5':0.5,
's4->s5':0.5,
's4-s*':0.5
}
#策略2
Pi_2={
's1->s1':0.6,
's1->s2':0.4,
's2->s1':0.3,
's2->s3':0.7,
's3->s4':0.5,
's3->s5':0.5,
's4->s5':0.1,
's4->s*':0.9
}
如何计算MDP下,一个策略$\pi$的状态价值函数
MDP->MRP
奖励函数 $$ r^\prime(s)=\sum_{a \in \mathcal{A}}\pi(a \mid s)r(s,a) $$
状态转移 $$ P^\prime(s^\prime|s)=\sum_{a \in \mathcal{A}}{\pi(a \mid s)P(s^\prime \mid s,a)} $$
Monte Carlo
$$ V^\pi(s)=\mathbb{E}\pi\left[G_t \mid S_t=s\right] \approx \frac{1}{N} \sum{i=1}^N G_t^{(i)} $$
步骤:
- 使用策略 $\pi$ 采样若干条序列: $$ s_0^{(i)} \stackrel{a_0^{(i)}}{\longrightarrow} r_0^{(i)}, s_1^{(i)} \stackrel{a_1^{(i)}}{\longrightarrow} r_1^{(i)}, s_2^{(i)} \stackrel{a_2^{(i)}}{\longrightarrow} \cdots \stackrel{a_{T-1}^{(i)}}{\longrightarrow} r_{T-1}^{(i)}, s_T^{(i)} $$
- 对每一条序列中的每一时间步 $t$ 的状态 $s$ 进行以下操作:
- 更新状态 $s$ 的计数器 $N(s) \leftarrow N(s)+1$;
- 更新状态 $s$ 的总回报 $M(s) \leftarrow M(s)+G_t$ ;
- 每一个状态的价值被估计为回报的平均值 $V(s)=M(s) / N(s)$ 。 根据大数定律,当 $N(s) \rightarrow \infty$ ,有 $V(s) \rightarrow V^\pi(s)$ 。计算回报的期望时,除了可以把所有的回报加起来除以次数,还有一种增量更新的方法。对于每个状态 $s$ 和对应回报$G$ ,进行如下计算:
- $N(s) \leftarrow N(s)+1$
- $V(s) \leftarrow V(s)+\frac{1}{N(s)}(G-V(S))$
import numpy as np
S = ["s1", "s2", "s3", "s4", "s5"] # 状态集合
A = ["保持s1", "前往s1", "前往s2", "前往s3", "前往s4", "前往s5", "概率前往"] # 动作集合
# 状态转移函数
P = {
"s1-保持s1-s1": 1.0,
"s1-前往s2-s2": 1.0,
"s2-前往s1-s1": 1.0,
"s2-前往s3-s3": 1.0,
"s3-前往s4-s4": 1.0,
"s3-前往s5-s5": 1.0,
"s4-前往s5-s5": 1.0,
"s4-概率前往-s2": 0.2,
"s4-概率前往-s3": 0.4,
"s4-概率前往-s4": 0.4,
}
# 奖励函数
R = {
"s1-保持s1": -1,
"s1-前往s2": 0,
"s2-前往s1": -1,
"s2-前往s3": -2,
"s3-前往s4": -2,
"s3-前往s5": 0,
"s4-前往s5": 10,
"s4-概率前往": 1,
}
gamma = 0.5 # 折扣因子
MDP = (S, A, P, R, gamma)
# 策略1,随机策略
Pi_1 = {
"s1-保持s1": 0.5,
"s1-前往s2": 0.5,
"s2-前往s1": 0.5,
"s2-前往s3": 0.5,
"s3-前往s4": 0.5,
"s3-前往s5": 0.5,
"s4-前往s5": 0.5,
"s4-概率前往": 0.5,
}
# 策略2
Pi_2 = {
"s1-保持s1": 0.6,
"s1-前往s2": 0.4,
"s2-前往s1": 0.3,
"s2-前往s3": 0.7,
"s3-前往s4": 0.5,
"s3-前往s5": 0.5,
"s4-前往s5": 0.1,
"s4-概率前往": 0.9,
}
# 把输入的两个字符串通过“-”连接,便于使用上述定义的P、R变量
def join(str1, str2):
return str1 + '-' + str2
def sample(MDP, Pi, timestep_max, number):
''' 采样函数,策略Pi,限制最长时间步timestep_max,总共采样序列数number '''
S, A, P, R, gamma = MDP
episodes = []
for _ in range(number):
episode = []
timestep = 0
s = S[np.random.randint(4)] # 随机选择一个除s5以外的状态s作为起点
# 当前状态为终止状态或者时间步太长时,一次采样结束
while s != "s5" and timestep <= timestep_max:
timestep += 1
rand, temp = np.random.rand(), 0
# 在状态s下根据策略选择动作
for a_opt in A:
temp += Pi.get(join(s, a_opt), 0)
if temp > rand:
a = a_opt
r = R.get(join(s, a), 0)
break
rand, temp = np.random.rand(), 0
# 根据状态转移概率得到下一个状态s_next
for s_opt in S:
temp += P.get(join(join(s, a), s_opt), 0)
if temp > rand:
s_next = s_opt
break
episode.append((s, a, r, s_next)) # 把(s,a,r,s_next)元组放入序列中
s = s_next # s_next变成当前状态,开始接下来的循环
episodes.append(episode)
return episodes
# # 采样5次,每个序列最长不超过20步
# episodes = sample(MDP, Pi_1, 20, 5)#策略为Pi_1
# 对所有采样序列计算所有状态的价值
def MC(episodes, V, N, gamma):
for episode in episodes:
G = 0
for i in range(len(episode) - 1, -1, -1): #一个序列从后往前计算
(s, a, r, s_next) = episode[i]
G = r + gamma * G
N[s] = N[s] + 1
V[s] = V[s] + (G - V[s]) / N[s]
timestep_max = 20
# 采样1000次,可以自行修改
episodes = sample(MDP, Pi_1, timestep_max, 1000)
gamma = 0.5
V = {"s1": 0, "s2": 0, "s3": 0, "s4": 0, "s5": 0}
N = {"s1": 0, "s2": 0, "s3": 0, "s4": 0, "s5": 0}
MC(episodes, V, N, gamma)
print("使用蒙特卡洛方法计算MDP的状态价值为\n", V)
最优策略
对于任意的状态 $s$ 都有 $V^\pi(s) \geq V^{\pi^{\prime}}(s)$ ,记 $\pi>\pi^{\prime}$ 。
于是在有限状态 和动作集合的 MDP 中,至少存在一个策略比其他所有策略都好或者 至少存在一个策略不差于其他所有策略,这个策略就是最优策略 (optimal policy) 。最优策略可能有很多个,我们都将其表示为 $\pi^(s)$
最优策略都有相同的状态价值函数,我们称之为最优状态价值函数, 表示为:
$$
V^(s)=\max \pi V^\pi(s), \quad \forall s \in \mathcal{S}
$$
同理,我们定义最优动作价值函数:
$$
Q^(s, a)=\max _\pi Q^\pi(s, a), \quad \forall s \in \mathcal{S}, a \in \mathcal{A}
$$
最优状态价值函数和最优动作价值函数之间的关系:
$$
Q^(s, a)=r(s,a)+\gamma\sum{s^\prime \in S}P(s^\prime \mid s,a)V^(s^\prime)
$$
最优状态价值是选择此时使最优动作价值最大的那一个动作时的状态价值
$$
V^(s)=\max_{a \in \mathcal{A}}Q^*(s,a)
$$
Bellman最优方程
根据 $V^(s)$ 和 $Q^(s, a)$ 的关系,我们可以得到贝尔曼最优方程 (Bellman optimality equation) : $$ \begin{gathered} V^(s)=\max {a \in \mathcal{A}}\left{r(s, a)+\gamma \sum{s^{\prime} \in \mathcal{S}} p\left(s^{\prime} \mid s, a\right) V^\left(s^{\prime}\right)\right} \ Q^(s, a)=r(s, a)+\gamma \sum_{s^{\prime} \in \mathcal{S}} p\left(s^{\prime} \mid s, a\right) \max _{a^{\prime} \in \mathcal{A}} Q^\left(s^{\prime}, a^{\prime}\right) \end{gathered} $$
DP优化
基于动态规划的强化学习算法主要有两种一是策略迭代,二是价值迭代
策略迭代:策略评估(使用贝尔曼期望方程->策略的状态价值函数)+策略提升
策略迭代算法
$$
\begin{aligned}
V^\pi(s) & =\mathbb{E}\pi\left[R_t+\gamma V^\pi\left(S{t+1}\right) \mid S_t=s\right] \
& =\sum_{a \in A} \pi(a \mid s)\left(r(s, a)+\gamma \sum_{s^{\prime} \in S} p\left(s^{\prime} \mid s, a\right) V^\pi\left(s^{\prime}\right)\right) \
\end{aligned}
$$