调用惯例
简要介绍
==调用惯例(Calling Conventions)==指计算机程序执行时调用函数或过程的一些约定,包括:
- 1.函数的参数是通过栈还是寄存器传递?
- 2.如果通过栈传递,顺序是怎样的,是从左至右入栈还是相反。
- 3.谁负责清理栈,是调用者还是被调用者?
针对这三个约定,不同的调用惯例有不同的实现,参考课本和搜索引擎,归纳如下
| 调用惯例 | 调用场合 | 传参方式 | 入栈顺序 | 传返回值 | 清理栈者 | 名字修饰 |
|---|---|---|---|---|---|---|
| cdecl | Windows API | 栈传参 | 从右至左压栈 | 寄存器(EAX) | 调用者函数 | _+函数名 |
| stdcall | C/C++ | 栈传参 | 从右至左压栈 | 寄存器(EAX) | 被调用者函数 | _+函数名+@+参数的字节数 |
| fastcall | GCC/Microsoft | 左DWORD用ECX和EDX,剩余栈传参 | 从右至左压栈 | 寄存器(EAX) | 被调用者函数 | @+函数名+@+参数字节数 |
程序分析
函数设置
main函数
#include<stdio.h>
int __cdecl add1(int a, int b);
int __stdcall add2(int a, int b);
int __fastcall add3(int a, int b);
int main(int argc, char *argv[])
{
//调用cdecl调用惯例下的add函数
add1(1,2);
//调用stdcall调用惯例下的add函数
add2(1,2);
//调用fastcall调用惯例下的add函数
add3(1,2);
return 0;
}
add函数
int __cdecl add1(int a, int b)//cdecl调用惯例下的add函数
{
return a + b;
}
int __stdcall add2(int a, int b)//stdcall调用惯例下的add函数
{
return a + b;
}
int __fastcall add3(int a, int b)//fastcall调用惯例下的add函数
{
return a + b;
}
分别对三种种调用惯例下的main(共用)和sub函数(区别所在)进行编译,生成二进制可执行文件,然后拖入ollydbg进行反汇编调试,观察main调用sub函数时栈状态的变化。
gcc -g callfuction.c -o deg_work1 #生成debug信息
Ollydbg提示Not a valid PE file,****.exe‘ is probably not a 32-bit Portable Executable.
发现Ollydbg只能编译32位的文件
gcc -g -m32 callfuction.c -o deg_work1 #生成带debug信息的32位二进制文件
在Linux里面编译一直报错
warning: implicit declaration of function ‘add’ [-Wimplicit-function-declaration]
原因原来是Windows下的调用约定可以是stdcall/cdecl/fastcall,这些标识加在函数名前面,如:
int __stdcall funca()
但在Linux下,如按照上面写法后,编译程序将导致编译错误,Linux下正确的语法如下:
int __attribute__ ((__stdcall__)) funca()
int __attribute__ ((__cdecl__)) funca()
程序反编译
main函数
; int __cdecl main(int argc, char **argv)
public _main ;main函数
_main proc near
var_4= dword ptr -4 ; int argc
argc= dword ptr 8 ; int argc
argv= dword ptr 0Ch ; char **argv
lea ecx, [esp+4] ; char **argv
and esp, 0FFFFFFF0h ;esp是栈指针 16字节对齐
push dword ptr [ecx-4] ; argc入栈
push ebp ; ebp入栈,保留基址
mov ebp, esp ; ebp指向栈顶
push ecx ; argv入栈
sub esp, 14h ; 20字节的栈空间
call ___main ; 调用___main函数
mov dword ptr [esp+4], 2 ; b
mov dword ptr [esp], 1 ; a
call _add1 ; 调用add1函数
mov dword ptr [esp+4], 2 ; b
mov dword ptr [esp], 1 ; a
call _add2@8 ; 调用add2函数
sub esp, 8 ; 开辟8字节的栈空间
mov edx, 2 ; b
mov ecx, 1 ; a
call @add3@8 ; 调用add3函数
mov eax, 0 ; 返回值
mov ecx, [ebp+var_4] ; argc
leave ; 恢复栈指针
lea esp, [ecx-4] ; 恢复栈指针
retn ; 返回
_main endp ; main函数结束
cdecl下的add1函数
名字修饰方式 _+函数名 _add1
; int __cdecl add1(int a, int b)
public _add1 ;
_add1 proc near ;
a= dword ptr 8 ;为变量a分配内存
b= dword ptr 0Ch ;为变量b分配内存
push ebp ;保存上一级函数的ebp
mov ebp, esp ;将当前函数的esp赋值给ebp
mov edx, [ebp+a] ;将ebp+a的值赋值给edx
mov eax, [ebp+b] ;将ebp+b的值赋值给eax
add eax, edx ;将eax和edx相加
pop ebp ;恢复上一级函数的ebp
retn ;返回
_add1 endp ;函数结束
stdcall下的add2函数
名字修饰方式 函数名+@+参数的字节数 _add2@8
; int __stdcall add2(int a, int b)
public _add2@8
_add2@8 proc near
a= dword ptr 8 ;为变量a分配内存
b= dword ptr 0Ch ;为变量b分配内存
push ebp ;保存上一级函数的ebp
mov ebp, esp ;将当前函数的esp赋值给ebp
mov edx, [ebp+a] ; 将ebp+a的值赋值给edx
mov eax, [ebp+b];将ebp+b的值赋值给eax
add eax, edx ;将eax和edx相加
pop ebp ;恢复上一级函数的ebp
retn 8 ;返回
_add2@8 endp ;函数结束
fastcall下的add3函数
名字修饰方式 @+函数名+@+参数字节数 @add3@8
; int __stdcall add3(int a, int b)
public @add3@8
@add3@8 proc near
a= dword ptr 8 ;为变量a分配内存
b= dword ptr 0Ch ;为变量b分配内存
push ebp ;保存上一级函数的ebp
mov ebp, esp ;将当前函数的esp赋值给ebp
sub esp, 8 ;为局部变量分配内存
mov [ebp+a], ecx ;将ecx的值赋值给ebp+a
mov [ebp+b], edx ;将edx的值赋值给ebp+b
mov edx, [ebp+a] ;将ebp+a的值赋值给edx
mov eax, [ebp+b] ;将ebp+b的值赋值给eax
add eax, edx ;将eax和edx相加
leave ;恢复上一级函数的ebp
retn ;返回
@add3@8 endp ;函数结束
OD分析
值得注意的是直接搜索这些函数名在od里面无法找到,实际上是因为od以可执行文件名命名其中的用户函数:
如可执行文件是test.exe,那么od分析出来的用户函数命名基本上都是test.XXXXXX之类的形式
然后如何快速找到函数入口(如果不是设置了messagebox这样的函数的话):
这篇文章给我们大概介绍了一下 【笔记】OllyDBG 找程序主函数入口地址总结_51CTO博客_ollydbg怎么找函数入口地址
- 找几个压栈指令
- 压栈完了之后就是对栈的初始化
- 通常在压栈指令之前都有一个跳转指令(这个有时地址偏移比较大)
我选择还是去设置messagebox,更好去找到函数调用点,缺点是程序会更加庞杂
#include<Windows.h>
int __cdecl add1(int a, int b);
int __stdcall add2(int a, int b);
int __fastcall add3(int a, int b);
int f;
int main(int argc, char* argv[])
{
MessageBox(0, NULL, NULL, MB_OK);
f = 0x778899;
//调用cdecl调用惯例下的add函数
add1(1, 2);
//调用stdcall调用惯例下的add函数
add2(1, 2);
//调用fastcall调用惯例下的add函数
add3(1, 2);
return 0;
}
int __cdecl add1(int a, int b)//cdecl调用惯例下的add函数
{
//MessageBox(0, (LPCWSTR)L"this is cdecl",(LPCWSTR)L"1", MB_OK);
f = 0x112233;
return a + b;
}
int __stdcall add2(int a, int b)//stdcall调用惯例下的add函数
{
// MessageBox(0, (LPCWSTR)L"this is stdcall", (LPCWSTR)L"2", MB_OK);
f = 0x223344;
return a + b;
}
int __fastcall add3(int a, int b)//fastcall调用惯例下的add函数
{
//MessageBox(0, (LPCWSTR)L"this is fastcall", (LPCWSTR)L"3", MB_OK);
f = 0x334455;
return a + b;
}
定位到打上断点
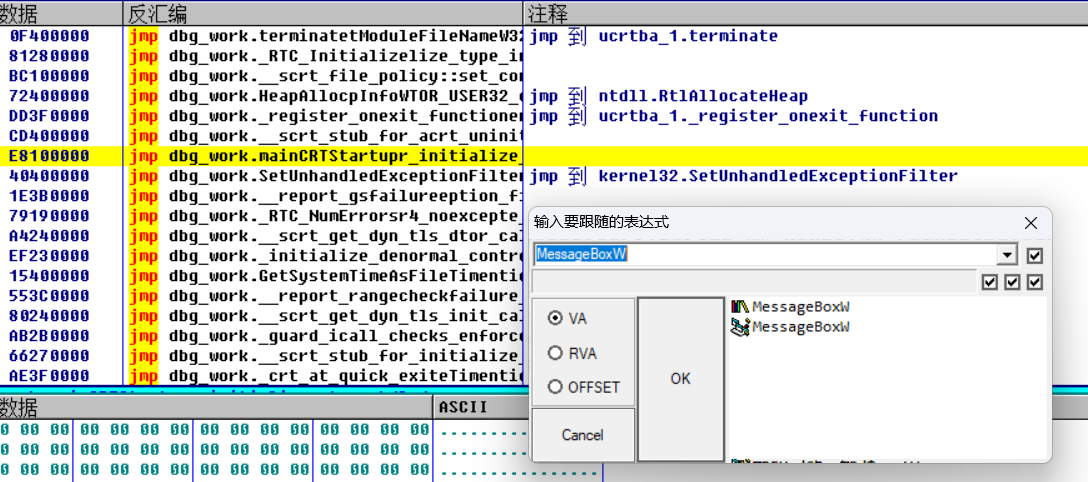
F2快速运行到main函数入口
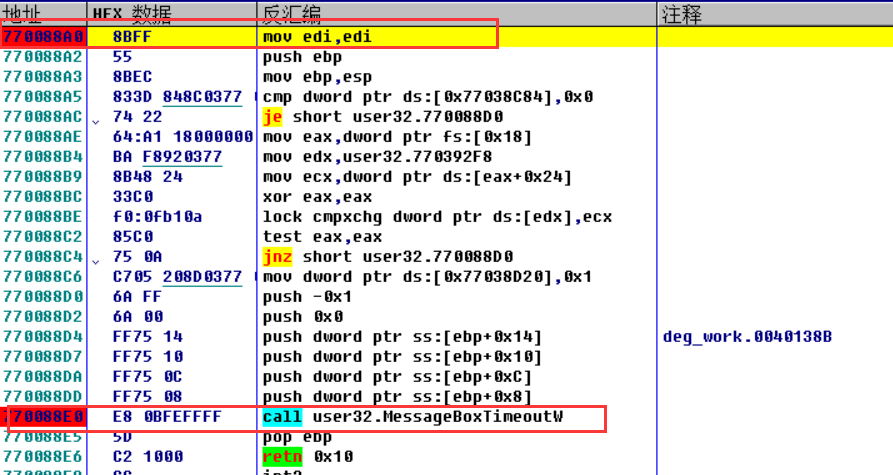
F8单步运行调试,出现弹窗,说明已经进入了main函数,然后在这个函数运行结束后会返回main函数,因此我们找到了函数调用入口
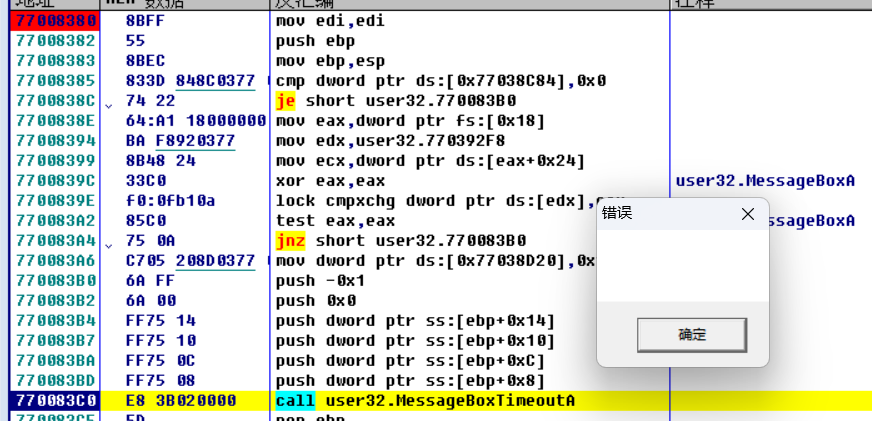
参数传递
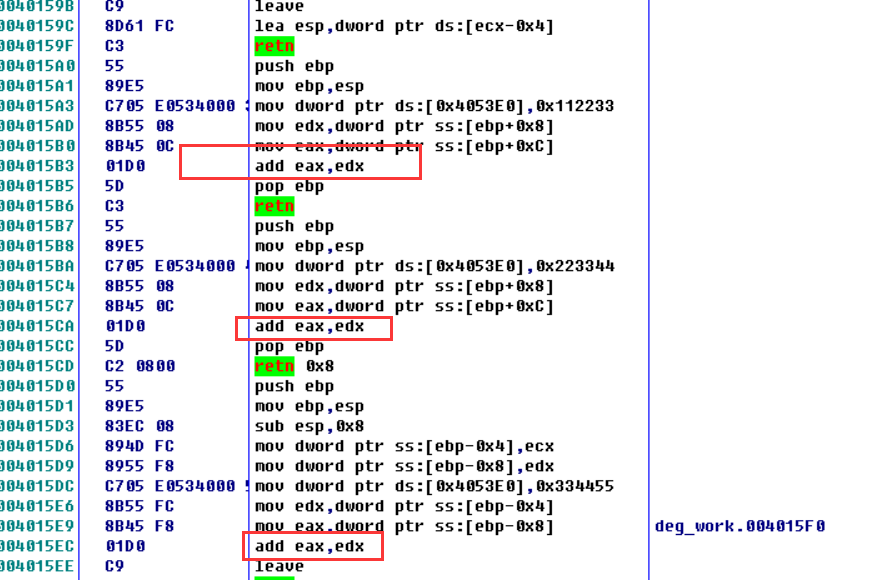
这里可以看到cdecl和stdcall的参数都是用栈传输 stdcall 左DWORD用ECX和EDX,剩余栈传参

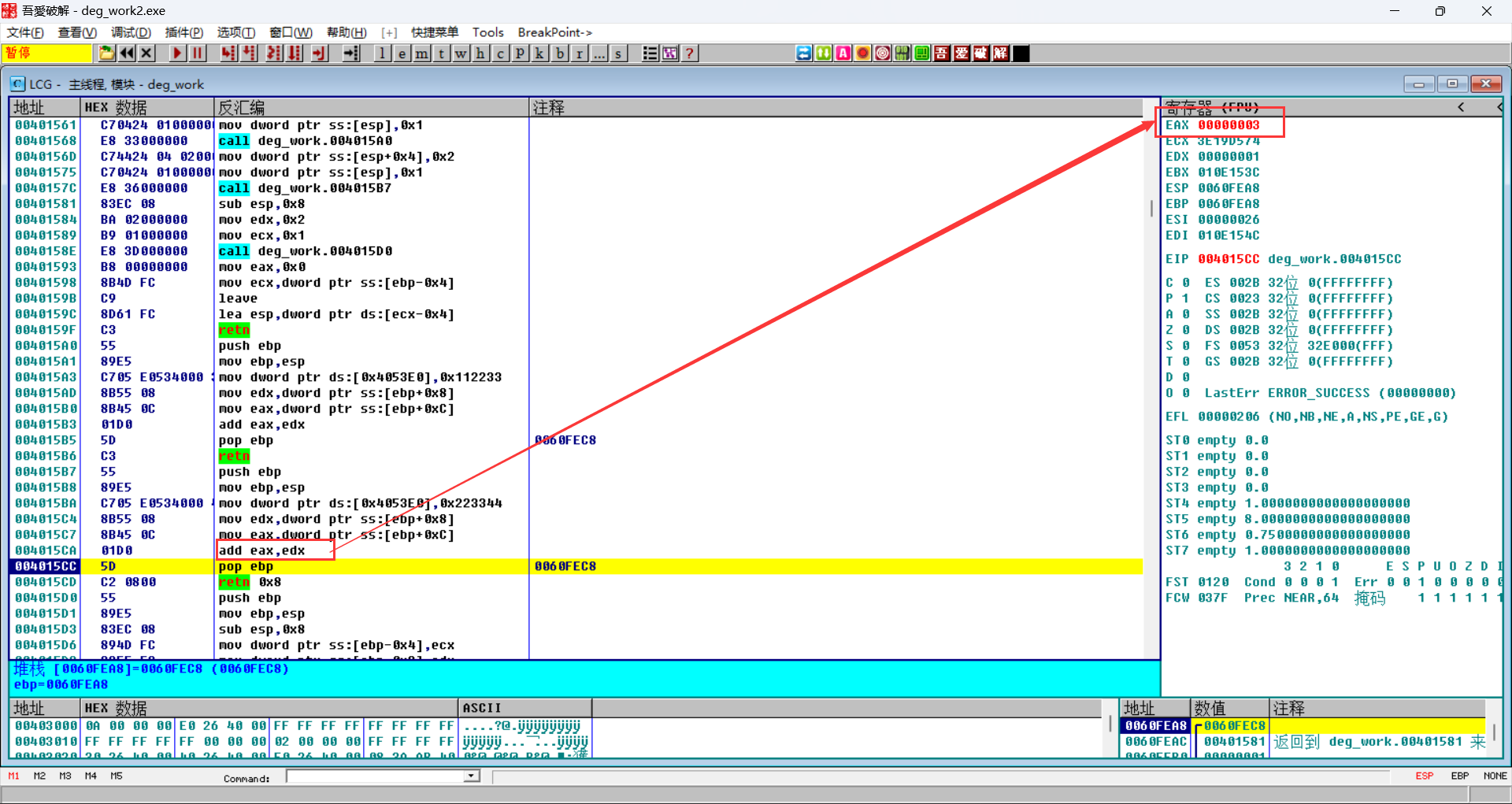
返回值
都用EAX将返回值返回
 入栈顺序
入栈顺序
都是从右向左依次压栈
栈清理
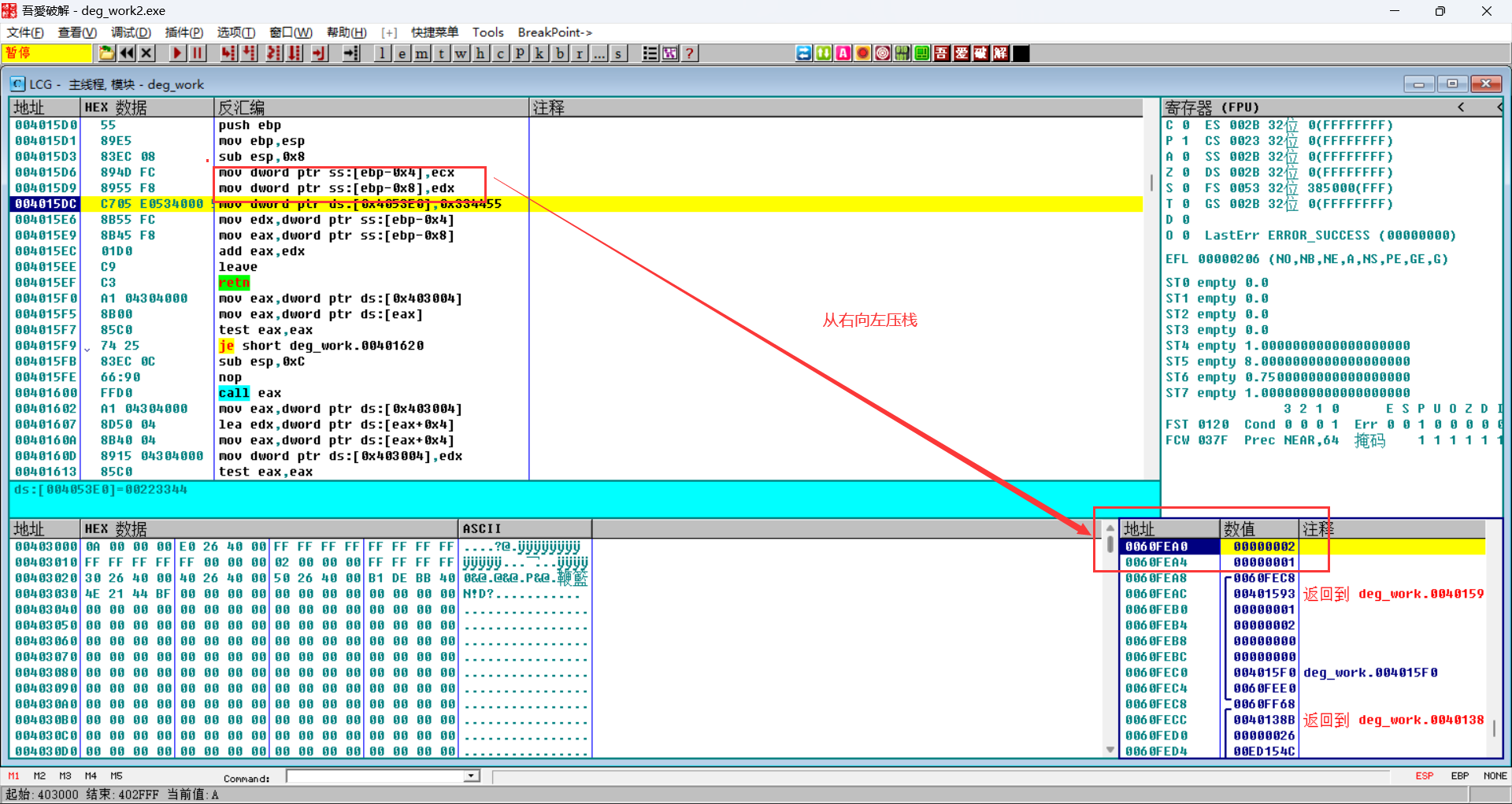
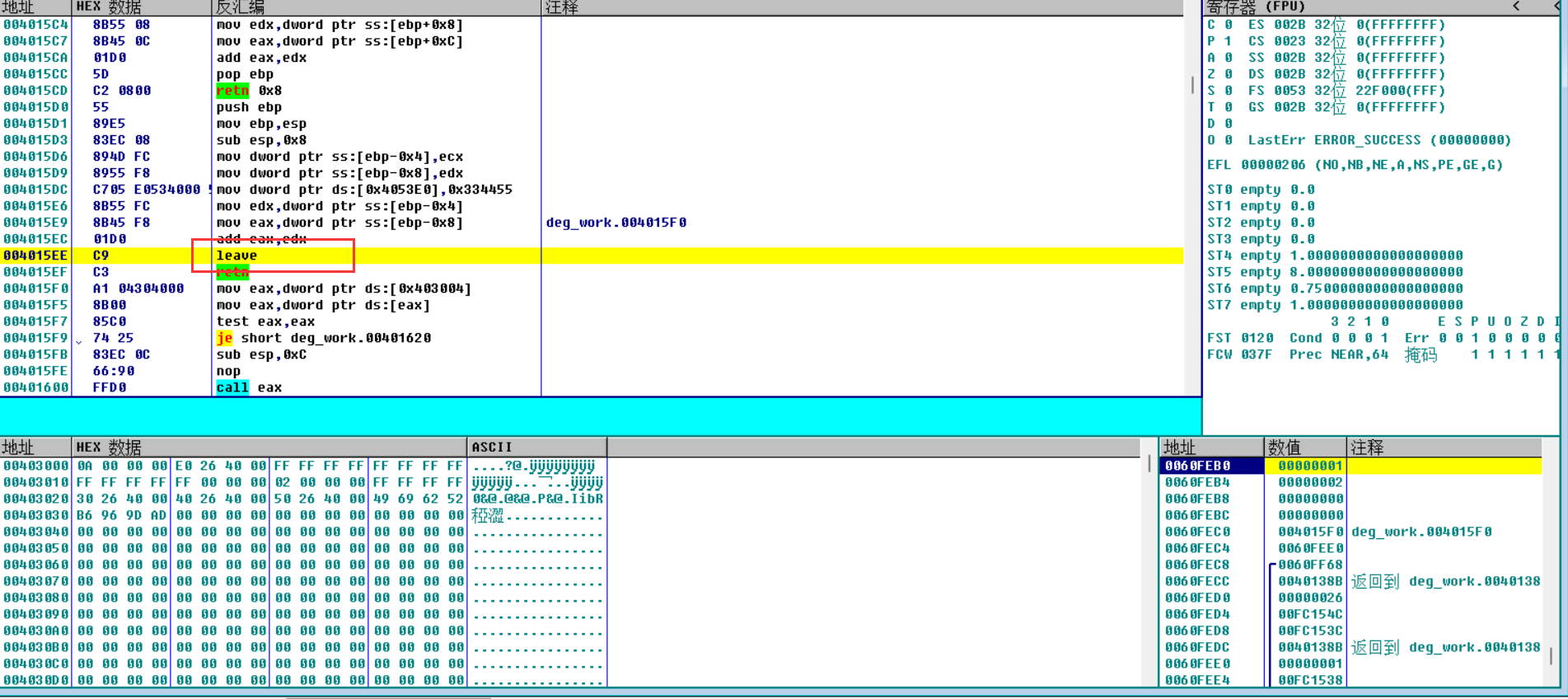
cdecl并不会自己清理栈空间,而是由main函数去清理
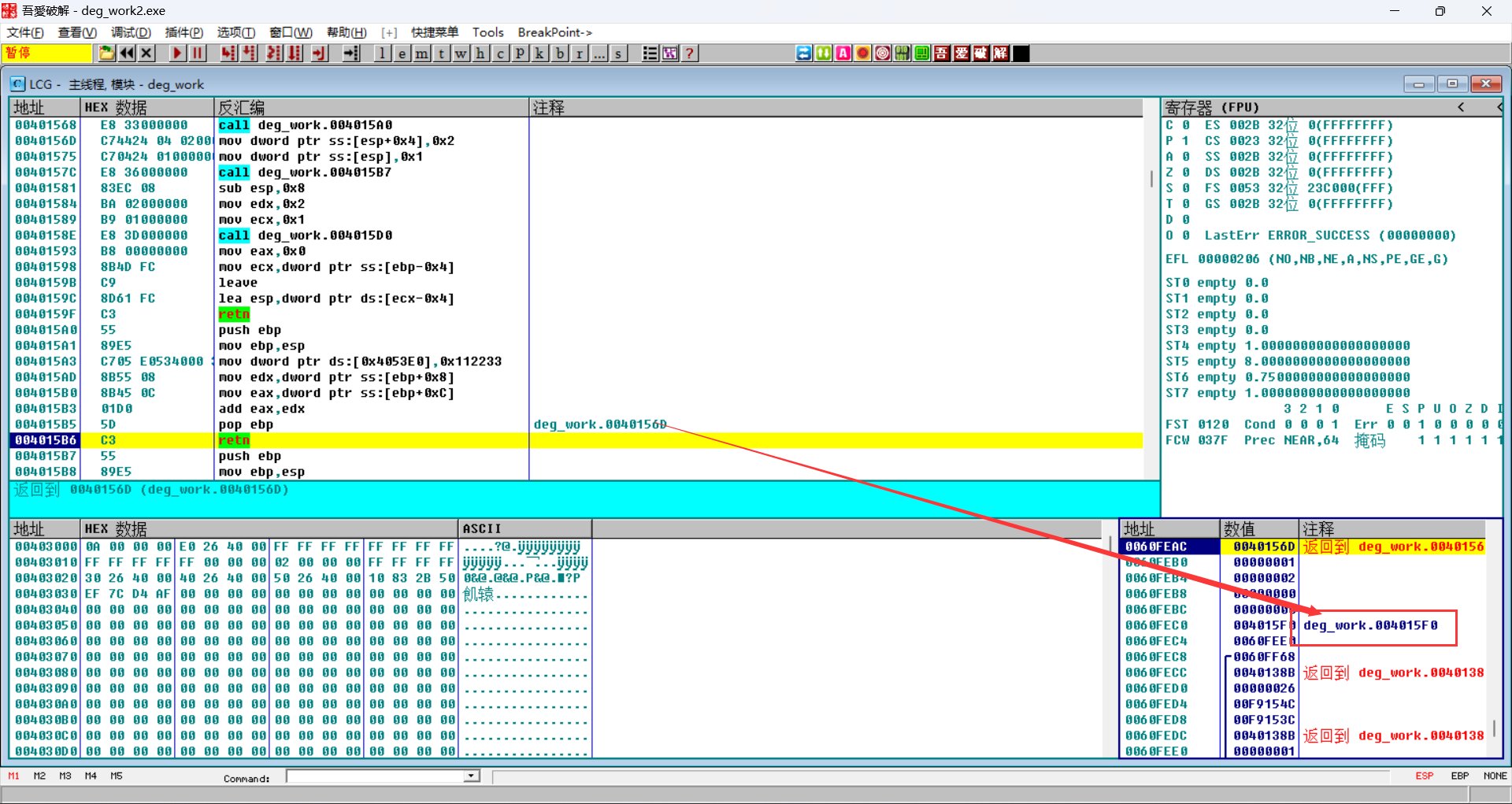
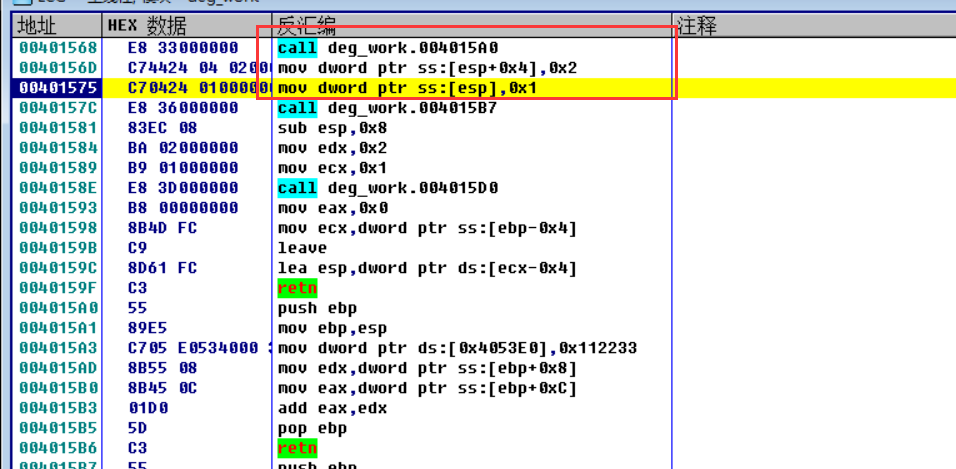
stdcall自己清理栈空间
可以看到这里返回的时候是retn 8,意味着还要弹出8个字节,而从栈中可以看到,ESP+8之后恰好把参数1和2弹出,即在add2(被调用者)函数内部完成参数清理
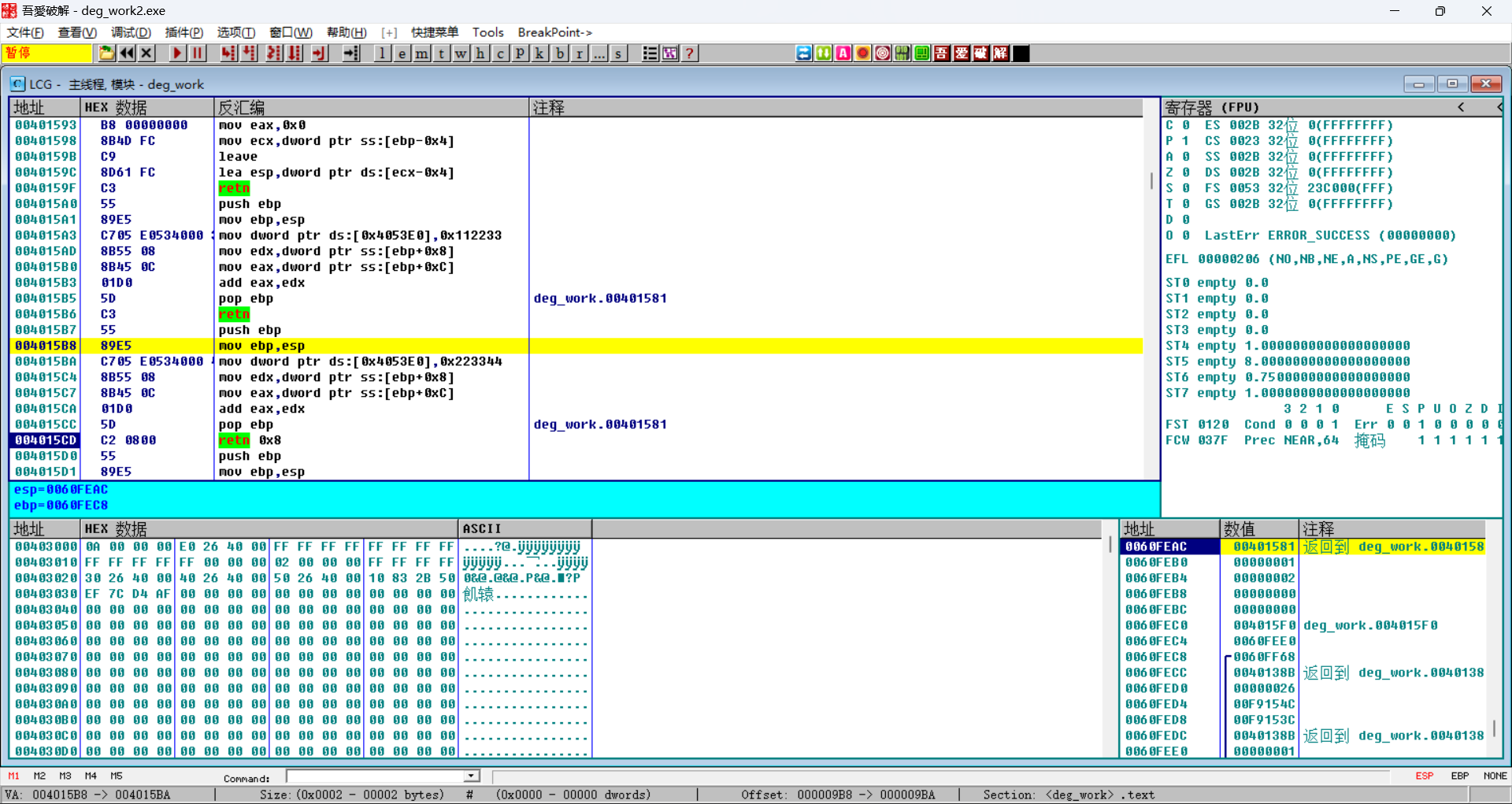
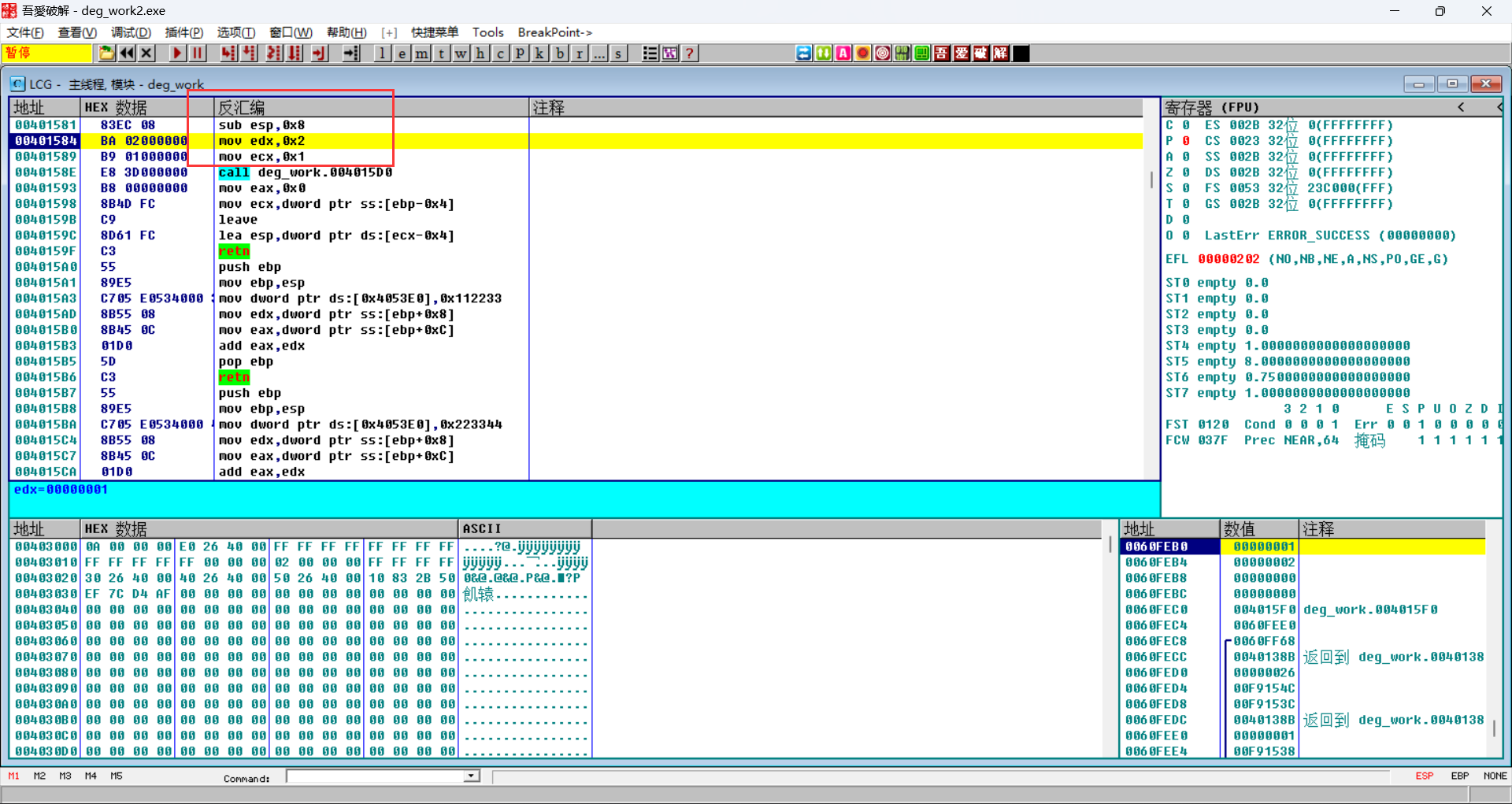
fastcall自己清理栈空间
O1-O3优化
优化等级设置
O的设置一共有5种常见的 O0:零,表示关闭所有优化选项, 也就是默认的参数,没有进行优化 参数 -O1、-O2、-O3 中,随着数字变大,代码的优化程度也越高,不过这在某种意义上来说,也是以牺牲程序的可调试性为代价的。 Os:是在-O2的基础上,去掉了那些会导致最终可执行程序增大的优化,如果想要更小的可执行程序,可以使用这个选项。 补充几个 Og 是在O1 的基础上,去掉了哪些影响调试的优化,所以最终是为了调试程序,可以使用该参数。不过光有这个参数也是不行的,这个参数只是告诉编译器,编译后的代码不要影响调试,但调试信息的生成还是靠 -g 参数的。 -Ofast 是在O3 的基础上,添加了一些非常规优化 可以使用gcc -Q – help=optimizers命令来查询
gcc -m32 callfuction.c -o deg_work2 -O1 //进行编译
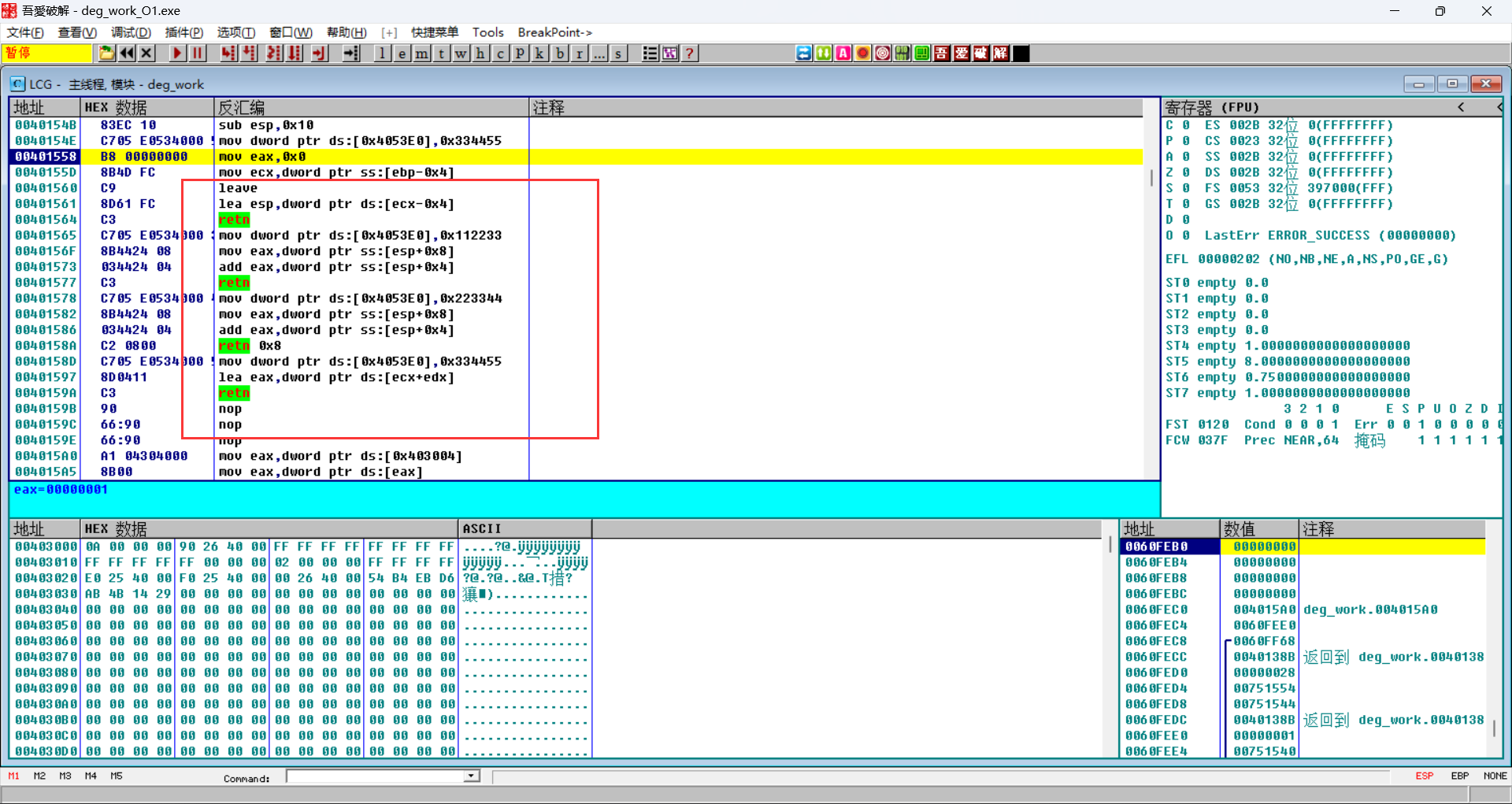
O1
相较于无优化的O1优化缩短可代码长度,减少了压栈操作,如ebp,无需去清理在该函数的栈空间,并且直接通过访问栈空间的方式进行运算,减少了对其他函数的访问。
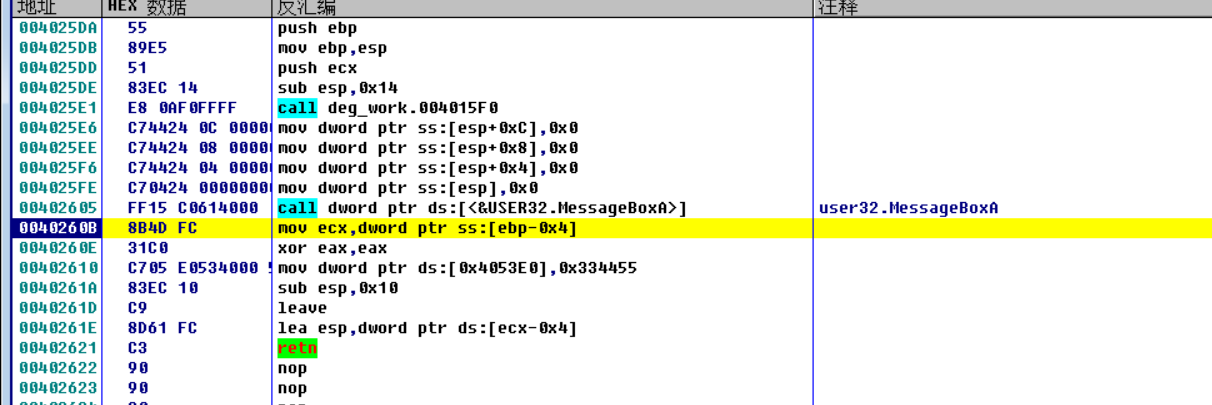
O2
重复的函数结构和无需要的子函数被优化掉了,最终剩余fastcall
O3
跟O2差不多,减少了冗余和一些内存空间的损耗