Python集成开发环境(IDE)
(1) Anaconda: https://www.continuum.io/ (推荐)
(2) IDLE: Python解释器默认工具
(3) PyCharm: https://www.jetbrains.com/pycharm/
(4) 实验数据集:Python的scikit-learn库中自带的鸢尾花数据集,可使用datasets.load_iris()载入。
需要描述清楚算法流程,包括加载数据、数据处理、创建模型,训练,预测,评估模型等。如果必须给出实现代码才能更好地说明问题时,也必须先有相关的文字叙述,然后才是代码,代码只是作为例证
鸢尾花数据集共收集了三类鸢尾花,即Setosa鸢尾花、Versicolour鸢尾花和Virginica鸢尾花,每一类鸢尾花收集了50条样本记录,共计150条。
数据集包括4个属性,分别为花萼的长、花萼的宽、花瓣的长和花瓣的宽。对花瓣我们可能比较熟悉,花萼是什么呢?花萼是花冠外面的绿色被叶,在花尚未开放时,保护着花蕾。四个属性的单位都是cm,属于数值变量,四个属性均不存在缺失值的情况,以下是各属性的一些统计值如下:
| 属性 | 最大值 | 最小值 | 均值 | 方差 |
|---|---|---|---|---|
| 萼长 | 7.9 | 4.3 | 5.84 | 0.83 |
| 萼宽 | 4.4 | 2.0 | 3.05 | 0.43 |
| 瓣长 | 6.9 | 1.0 | 3.76 | 1.76 |
| 瓣宽 | 2.5 | 0.1 | 1.20 | 0.76 |
KNN算法
算法原理
存在一个样本数据集合,也称为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类对应的关系。输入没有标签的数据后,将新数据中的每个特征与样本集中数据对应的特征进行比较,提取出样本集中特征最相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前k个最相似的数据,这就是k近邻算法中k的出处,通常k是不大于20的整数。最后选择k个最相似数据中出现次数最多的分类作为新数据的分类。
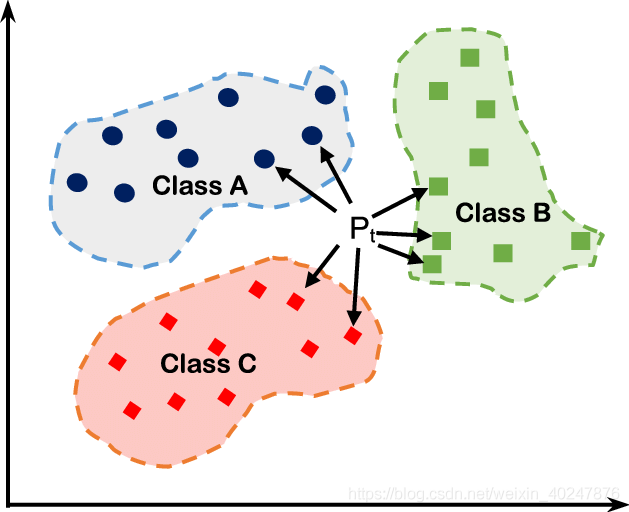
基本概念
计算距离 常用到的距离计算公式如下:
-
欧几里得距离(欧氏距离):
$d=\sqrt{(x_{1}-x_{2})^{2}+(y_{1}-y_{2})^{2}}$
-
曼哈顿距离
-
闵可夫斯基距离
-
切比雪夫距离
-
马氏距离
-
余弦相似度
-
皮尔逊相关系数
-
汉明距离
寻找最近邻数据
将所有距离进行升序排序,确定K值,最近的K个邻居即距离最短的K个数据。 关于K值得选择问题:
- K 值的选择会对算法的结果产生重大影响。
- K值较小意味着只有与测试数据较近的训练实例才会对预测结果起作用,容易发生过拟合。
- 如果 K 值较大,优点是可以减少学习的估计误差,但缺点是学习的近似误差增大,这时与测试数据较远的训练实例也会对预测起作用,使预测发生错误。
- 在实际应用中,K 值一般选择一个较小的数值,通常采用交叉验证的方法来选择最优的 K 值。随着训练实例数目趋向于无穷和 K=1 时,误差率不会超过贝叶斯误差率的2倍,如果K也趋向于无穷,则误差率趋向于贝叶斯误差率。(贝叶斯误差可以理解为最小误差)
三种交叉验证方法:
- Hold-Out: 随机从最初的样本中选出部分,形成交叉验证数据,而剩余的就当做训练数据。 一般来说,少于原本样本三分之一的数据被选做验证数据。常识来说,Holdout 验证并非一种交叉验证,因为数据并没有交叉使用。
- K-foldcross-validation:K折交叉验证,初始采样分割成K个子样本,一个单独的子样本被保留作为验证模型的数据,其他K-1个样本用来训练。交叉验证重复K次,每个子样本验证一次,平均K次的结果或者使用其它结合方式,最终得到一个单一估测。这个方法的优势在于,同时重复运用随机产生的子样本进行训练和验证,每次的结果验证一次,10折交叉验证是最常用的。
- Leave-One-Out Cross Validation:正如名称所建议, 留一验证(LOOCV)意指只使用原本样本中的一项来当做验证资料, 而剩余的则留下来当做训练资料。 这个步骤一直持续到每个样本都被当做一次验证资料。 事实上,这等同于 K-fold 交叉验证是一样的,其中K为原本样本个数。
决策分类
明确K个邻居中所有数据类别的个数,将测试数据划分给个数最多的那一类。即由输入实例的 K 个最临近的训练实例中的多数类决定输入实例的类别。 最常用的两种决策规则:
- 多数表决法:多数表决法和我们日常生活中的投票表决是一样的,少数服从多数,是最常用的一种方法。
- 加权表决法:有些情况下会使用到加权表决法,比如投票的时候裁判投票的权重更大,而一般人的权重较小。所以在数据之间有权重的情况下,一般采用加权表决法。
说明:KNN没有显示的训练过程,它是“懒惰学习”的代表,它在训练阶段只是把数据保存下来,训练时间开销为0,等收到测试样本后进行处理。
1)计算待分类点与已知类别的点之间的距离
2)按照距离递增次序排序
3)选取与待分类点距离最小的K个点
4)确定前K个点所在类别的出现次数
5)返回前K个点出现次数最高的类别作为待分类点的预测分类
代码实现
初始化数据集
初始化训练集和测试集。训练集一般为两类或者多种类别的数据;测试集一般为一个数据。
iris = load_iris()
data = iris.data
label = iris.target
# 划分训练集和测试集
train_set, test_set, train_label, test_label = train_test_split(data, label, test_size=0.2)
数据处理
归一化处理
train_set = (train_set - train_set.min(*axis*=0)) / (train_set.max(*axis*=0) - train_set.min(*axis*=0))
test_set = (test_set - test_set.min(*axis*=0)) / (test_set.max(*axis*=0) - test_set.min(*axis*=0))
定义距离
def distance(v1, v2):
return np.linalg.norm(v1 - v2)#计算两个向量的距离 欧式距离
欧几里得距离$d=\sqrt{(x_{1}-x_{2})^{2}+(y_{1}-y_{2})^{2}}$
创建模型和预测
首先,创建一个Knn实例。然后,在验证集上进行k-fold交叉验证。选择不同的k值,根据验证结果,选择最佳的k值。
def predict(train_set, train_label, test_set, k):
# 计算测试集中每个样本与训练集中所有样本的距离
distances = []
for i in range(len(train_set)):
distances.append(distance(test_set, train_set[i]))
# 对距离进行排序
distances = np.array(distances)
sort_index = distances.argsort()
# 统计前k个样本的标签
class_count = {}
for i in range(k):
label = train_label[sort_index[i]]
class_count[label] = class_count.get(label, 0) + 1
# 返回前k个样本中出现次数最多的标签
max_count = 0
for key, value in class_count.items():
if value > max_count:
max_count = value
max_index = key
return max_index
def knn(train_set, train_label, test_set, test_label, k):
right_count = 0
for i in range(len(test_set)):
predict_label = predict(train_set, train_label, test_set[i], k)
if predict_label == test_label[i]:
right_count += 1
return right_count / len(test_set)
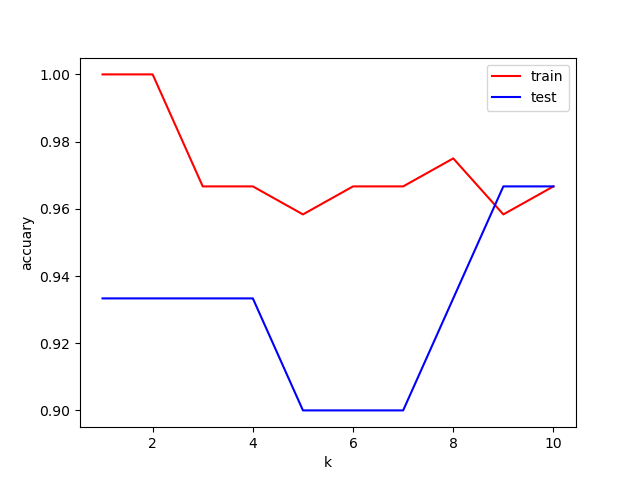
寻找最佳的邻居数
def find_best_k(train_set, train_label, test_set, test_label):
train_accuary = []
test_accuary = []
best_k = 0
#k取值从1到10
for k in range(1, 11):
train_accuary.append(knn(train_set, train_label, train_set, train_label, k))
test_accuary.append(knn(train_set, train_label, test_set, test_label, k))
#绘制k值与准确率的关系
plt.plot(range(1, 11), train_accuary, color='red', label='train')
plt.plot(range(1, 11), test_accuary, color='blue', label='test')
plt.xlabel('k')
plt.ylabel('accuary')
plt.legend()
plt.show()
#找到最佳k值
best_k = test_accuary.index(max(test_accuary)) + 1
return best_k
通过可视化分析得知,在n_neighbors取到:4,8,效果还可以,但是推荐使用5,因为综合训练集和测试集,还是不错的
图形化
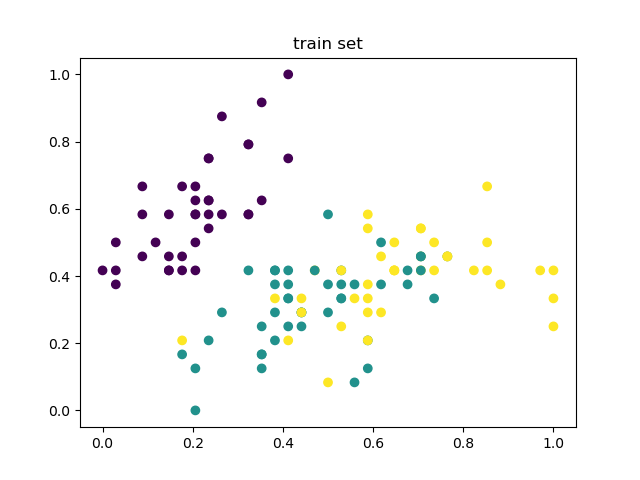
def show(train_set, train_label, test_set, test_label, k):
# 绘制训练集
plt.title('train set')
plt.scatter(train_set[:, 0], train_set[:, 1], c=train_label)
plt.show()
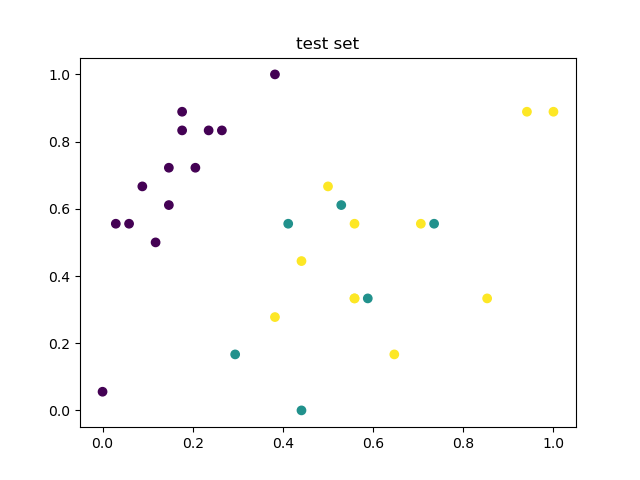
# 绘制测试集
plt.title('test set')
plt.scatter(test_set[:, 0], test_set[:, 1], c=test_label)
plt.show()
# 绘制预测结果
plt.title('predict result')
predict_label = []
for i in range(len(test_set)):
predict_label.append(predict(train_set, train_label, test_set[i], k))
plt.scatter(test_set[:, 0], test_set[:, 1], c=predict_label)
plt.show()
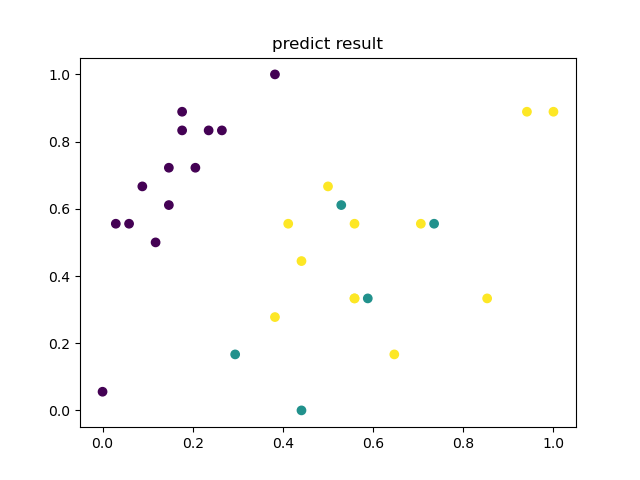
评估KNN
accuracy = knn(train_set, train_label, test_set, test_label, best_k)
# 计算准确率
print(accuracy)

from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# 载入数据
iris = datasets.load_iris() # 已经内置了鸢尾花数据集
x = iris.data # 输入4个特征
y = iris.target # 输出类别
# 随机划分数据集,默认25%测试集75%训练集
x_train, x_test, y_train, y_test = train_test_split(x, y)
# 创建一个KNN分类器对象,并设置K=5,
clf = KNeighborsClassifier(n_neighbors=5) # clf意为Classifier
# 训练
clf.fit(x_train, y_train) # 用训练数据拟合分类器模型
# 测试
pre_test = clf.predict(x_test) # 得到测试集的预测结果
# 计算正确率
print('正确率:%.3f' % accuracy_score(y_test, pre_test))
# 由于数据集是随机划分,每次得到正确率自然不同,可以设置random_state让随机一致
#画出预测结果
import matplotlib.pyplot as plt
plt.scatter(x_test[:,0],x_test[:,1],c=pre_test)
plt.show()

算法评价
优点:
1)算法简单,理论成熟,既可以用来做分类也可以用来做回归。
2)可用于非线性分类。
3)没有明显的训练过程,而是在程序开始运行时,把数据集加载到内存后,不需要进行训练,直接进行预测,所以训练时间复杂度为0。
4)由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属的类别,因此对于类域的交叉或重叠较多的待分类样本集来说,KNN方法较其他方法更为适合。
5)该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量比较小的类域采用这种算法比较容易产生误分类情况。
缺点:
1)需要算每个测试点与训练集的距离,当训练集较大时,计算量相当大,时间复杂度高,特别是特征数量比较大的时候。
2)需要大量的内存,空间复杂度高。
3)样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少),对稀有类别的预测准确度低。
4)是lazy learning方法,基本上不学习,导致预测时速度比起逻辑回归之类的算法慢。
DBSCAN算法
算法原理
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种基于密度的空间聚类算法。该算法将具有足够密度的区域划分为簇,并在具有噪声的空间数据库中发现任意形状的簇,它将簇定义为密度相连的点的最大集合。
这类密度聚类算法一般假定类别可以通过样本分布的紧密程度决定。同一类别的样本,他们之间的紧密相连的,也就是说,在该类别任意样本周围不远处一定有同类别的样本存在。通过将紧密相连的样本划为一类,这样就得到了一个聚类类别。通过将所有各组紧密相连的样本划为各个不同的类别,则我们就得到了最终的所有聚类类别结果。
基本概念
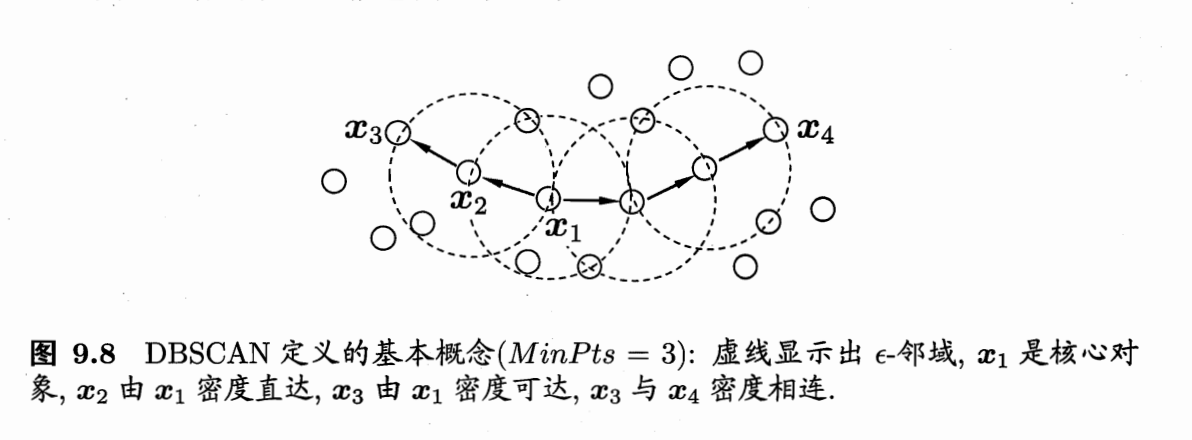
若给定数据集$D={x_1,x_2,…,x_i}$
$\epsilon$-邻域: 对 $\boldsymbol{x}_j \in D$, 其 $\epsilon$-邻域包含样本集 $D$ 中与 $\boldsymbol{x}j$ 的距离不大于 $\epsilon$ 的样本,即 $N\epsilon\left(\boldsymbol{x}_j\right)=\left{\boldsymbol{x}_i \in D \mid \operatorname{dist}\left(\boldsymbol{x}_i, \boldsymbol{x}_j\right) \leqslant \epsilon\right}$;
1、核心对象:若$x_j$的$\epsilon$邻域内有超过MinPts个样本,$x_j$是一个核心对象;
2、密度直达:$x_i$是核心对象,$x_j$位于$x_i$的$\epsilon$邻域内,则称$x_j$由$x_i$密度直达;
3、密度可达:对 $\boldsymbol{x}_i$ 与 $\boldsymbol{x}_j$, 若存在样本序列 $\boldsymbol{p}_1, \boldsymbol{p}_2, \ldots, \boldsymbol{p}_n$, 其中 $\boldsymbol{p}_1=\boldsymbol{x}_i, \boldsymbol{p}_n \doteq \boldsymbol{x}j$ 且 $\boldsymbol{p}{i+1}$ 由 $\boldsymbol{p}_i$ 密度直达, 则称 $\boldsymbol{x}_j$ 由 $\boldsymbol{x}_i$ 密度可达;
4、密度相连:对 $\boldsymbol{x}_i$ 与 $\boldsymbol{x}_j$, 若存在 $\boldsymbol{x}_k$ 使得 $\boldsymbol{x}_i$ 与 $\boldsymbol{x}_j$ 均由 $\boldsymbol{x}_k$ 密度可达, 则称 $\boldsymbol{x}_i$ 与 $\boldsymbol{x}_j$ 密度相连.
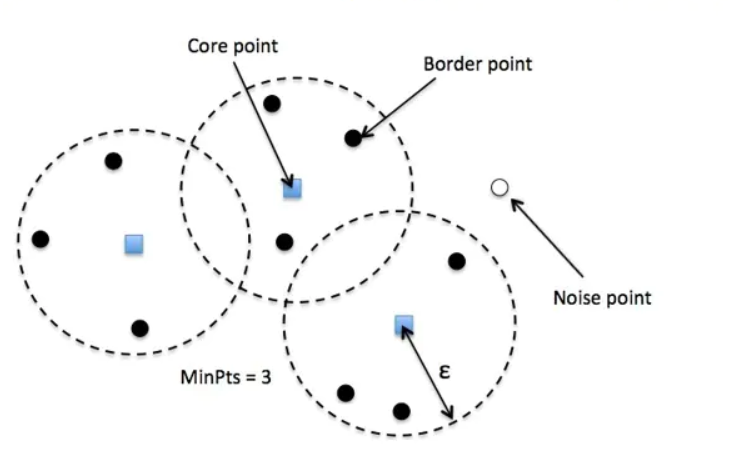
- 核心点 (Core point)。若样本 $x_i$ 的 $\varepsilon$ 邻域内至少包含了MinPts个样本, 即 $N_{\varepsilon}\left(X_i\right) \geq$ MinPts,则称样本点 $x_i$ 为核心点。
- 边界点 (Border point)。若样本 $x_i$ 的 $\varepsilon$ 邻域内包含的样本数目小于MinPts,但是它在其他核心点的邻域内,则称样本点 $x_i$ 为边界点。
- 噪音点 (Noise)。既不是核心点也不是边界点的点
簇的定义
DBSCAN 算法对簇的定义很简单,由密度可达关系导出的最大密度相连的样本集合,即为最终聚类的一个簇。
算法流程
输入: 样本集 $\mathrm{D}=\left(x_1, x_2, \ldots, x_m\right)$ ,邻域参数 $(\epsilon$, MinPts $)$ ,样本距离度量方式 输出: 簇划分C.
- 初始化核心对象集合 $\Omega=\emptyset ,$ 初始化聚类簇数 $\mathrm{k}=0$ ,初始化末访问样本集合 $\Gamma=\mathrm{D}$ ,簇划分 $\mathrm{C}=\emptyset$
- 对于 $j=1,2, \ldots m$ ,按下面的步㝡找出所有的核心对象: a) 通过距离庹量方式,找到样本 $x_j$ 的 $\epsilon$-邻域子样本集 $N_\epsilon\left(x_j\right)$ b) 如果子样本集样本个数满足 $\left|N_\epsilon\left(x_j\right)\right| \geq \operatorname{MinPts}$ , 将样本 $x_j$ 加入核心对象样本集合: $\Omega=\Omega \cup\left{x_j\right}$
- 如果核心对象集合 $\Omega=\emptyset$ ,则算法结束,否则转入步骤4.
- 在核心对象集合 $\Omega$ 中,随机选择一个核心对象 $O$ ,初始化当前笶核心对象队列 $\Omega_{c u r}={o}$ ,初始化类别序号 $\mathrm{k}=\mathrm{k}+1$ ,初始化当前簇样本集合 $C_k={o}$ ,更新末访问样本集合 $\Gamma=\Gamma-{o}$
- 如果当前笶核心对象队列 $\Omega_{c u r}=\emptyset$, 则当前聚类箷 $C_k$ 生成完毕,更新簇划分 $\mathrm{C}=\left{C_1, C_2, \ldots, C_k\right}$ ,更新核心对象集合 $\Omega=\Omega-C_k$ ,转入步 骤3。否则更新核心对象集合 $\Omega=\Omega-C_k$ 。
- 在当前簇核心对象队列 $\Omega_{c u r}$ 中取出一个核心对象 $o^{\prime}$, 通过邻域距离阈值 $\epsilon$ 找出所有的 $\epsilon$-邻域子样本集 $N_\epsilon\left(o^{\prime}\right)$ ,令 $\Delta=N_\epsilon\left(o^{\prime}\right) \cap \Gamma$ ,更新当前簇样本 集合 $C_k=C_k \cup \Delta$ ,更新末访问样本集合 $\Gamma=\Gamma-\Delta$ ,更新 $\Omega_{c u r}=\Omega_{c u r} \cup(\Delta \cap \Omega)-o^{\prime}$ ,转入步噔5. 输出结果为: 簇划分 $\mathrm{C}=\left{C_1, C_2, \ldots, C_k\right}$
代码实现
加载数据
iris = load_iris()
data = iris.data
label = iris.target
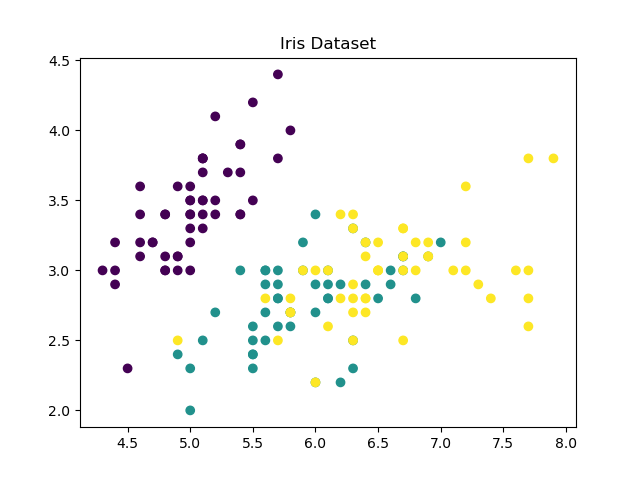
plt.title('Iris Dataset')
plt.scatter(data[:, 0], data[:, 1], c=label)
plt.show()
计算距离
这里的距离度量是用的二范数或者欧几里得范数
The $L_2$-norm (or 2-norm, or Euclidean norm) $$ |\boldsymbol{x}|2=\sqrt{\sum{i=1}^n x_i^2} $$ 然后下方这个函数就主要负责距离的查询
选择每次的首个核心点,并传入参数epsilon和min_points进行首次迭代
def region_query(data, point_id, eps):
# Find all points within eps distance of point
neighbors = []
for i in range(0, len(data)):
if np.linalg.norm(data[i] - data[point_id]) < eps:
neighbors.append(i)
return neighbors
寻找近邻点
首个核心点迭代完成后,对它进行移动,直到出现不满足阈值条件的样本点为止
def expandCluster(data,label,point_id,cluster_id,eps,min_points):
# 返回所有近邻点
neighbors = region_query(data,point_id, eps)
# print(neighbors)
# 如果点的密度小于min_points,则为噪声点
if len(neighbors) < min_points:
label[point_id] = -1
return False
# 如果点的密度大于min_points,则为核心点
else:
# 为核心点赋新簇标签
label[point_id] = cluster_id
for neighbor in neighbors:
label[neighbor] = cluster_id#为eps半径内的点赋新簇标签
# 遍历所有近邻点
while len(neighbors) > 0:#对近邻点进行扩展
current_point = neighbors[0]#取出第一个点
query_results = region_query(data,current_point, eps)#找出该点的所有近邻点
if len(query_results) >= min_points:#如果该点的密度大于min_points,则为核心点
for i in range(0, len(query_results)):#遍历所有近邻点
result_point = query_results[i]
if label[result_point] == -1:#如果该点为噪声点,则赋新簇标签
label[result_point] = cluster_id
elif label[result_point] == 0:#如果该点未访问过,则赋新簇标签,并加入neighbors
label[result_point] = cluster_id
neighbors.append(result_point)
neighbors.remove(current_point)#删除当前点
return True
dbscan
初始化一个空的分类列表,对其中每个未分类点进行调用上述函数
def dbscan(data,eps,min_points):
cluster_id = 1
label = [0] * len(data)#初始化一个空的分类列表
for point_id in range(0, len(data)):
if label[point_id] == 0:#如果该点未访问过
if expandCluster(data,label,point_id,cluster_id,eps,min_points):
#可变类型:类似 c++ 的引用传递,如 列表,字典,类等
cluster_id = cluster_id + 1
print(cluster_id)
return label
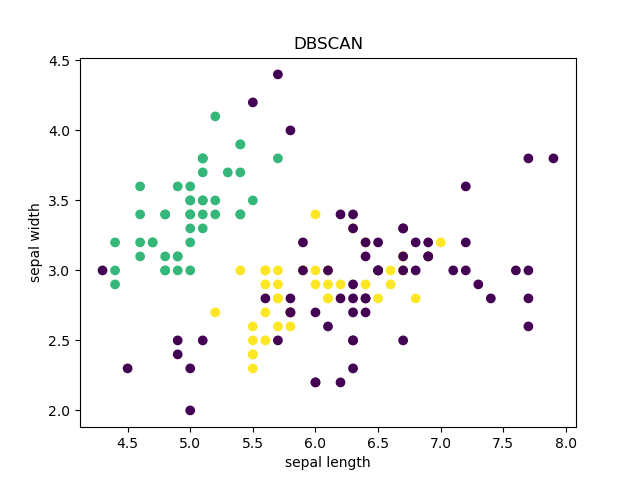
可视化模型结果
按照前两个参数进行画图
plt.title('DBSCAN')
plt.scatter(data[:, 0], data[:, 1], c=label_pred)
plt.xlabel('sepal length')
plt.ylabel('sepal width')
#图例
plt.show()
评估K-means模型
print("轮廓系数为:",metrics.silhouette_score(data, label_pred, metric='euclidean'))

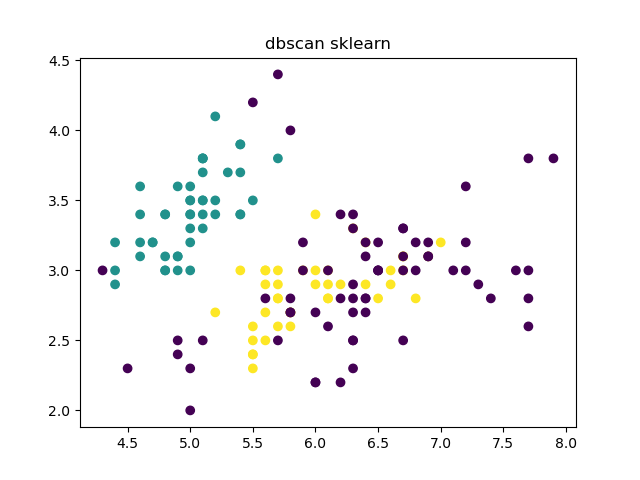
与sklearn的对比
from sklearn.cluster import DBSCAN
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
from sklearn import metrics
iris=load_iris()
data=iris.data
label=iris.target
db = DBSCAN(eps=0.46, min_samples=11).fit(data)
skl_labels = db.labels_
plt.title('dbscan sklearn')
plt.scatter(data[:, 0], data[:, 1], c=skl_labels)
plt.show()
完整代码
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
def region_query(data, point_id, eps):
# Find all points within eps distance of point
neighbors = []
for i in range(0, len(data)):
if np.linalg.norm(data[i] - data[point_id]) < eps:
neighbors.append(i)
return neighbors
def expandCluster(data,label,point_id,cluster_id,eps,min_points):
# 返回所有近邻点
neighbors = region_query(data,point_id, eps)
# print(neighbors)
# 如果点的密度小于min_points,则为噪声点
if len(neighbors) < min_points:
label[point_id] = -1
return False
# 如果点的密度大于min_points,则为核心点
else:
# 为核心点赋新簇标签
label[point_id] = cluster_id
for neighbor in neighbors:
label[neighbor] = cluster_id#为eps半径内的点赋新簇标签
# 遍历所有近邻点
while len(neighbors) > 0:#对近邻点进行扩展
current_point = neighbors[0]#取出第一个点
query_results = region_query(data,current_point, eps)#找出该点的所有近邻点
if len(query_results) >= min_points:#如果该点的密度大于min_points,则为核心点
for i in range(0, len(query_results)):#遍历所有近邻点
result_point = query_results[i]
if label[result_point] == -1:#如果该点为噪声点,则赋新簇标签
label[result_point] = cluster_id
elif label[result_point] == 0:#如果该点未访问过,则赋新簇标签,并加入neighbors
label[result_point] = cluster_id
neighbors.append(result_point)
neighbors.remove(current_point)#删除当前点
return True
#初始化一个空的分类列表,对其中每个未分类点进行调用上述函数
def dbscan(data,eps,min_points):
cluster_id = 1
label = [0] * len(data)#初始化一个空的分类列表
for point_id in range(0, len(data)):
if label[point_id] == 0:#如果该点未访问过
if expandCluster(data,label,point_id,cluster_id,eps,min_points):
#可变类型:类似 c++ 的引用传递,如 列表,字典,类等
cluster_id = cluster_id + 1
print(cluster_id)
return label
def showCluster(data, label):
n_clusters_ = len(set(label)) - (1 if -1 in label else 0)
print(n_clusters_)
# Black removed and is used for noise instead.
unique_labels = set(label)
colors = [plt.cm.Spectral(each)
for each in np.linspace(0, 1, len(unique_labels))]
for k, col in zip(unique_labels, colors):
if k == -1:
# Black used for noise.
col = [0, 0, 0, 1]
class_member_mask = (label == k)
xy = data[class_member_mask]
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),
markeredgecolor='k', markersize=14)
plt.title('Estimated number of clusters: %d' % n_clusters_)
plt.show()
if __name__ == '__main__':
iris = load_iris()
data = iris.data
label = iris.target
plt.title('Iris Dataset')
plt.scatter(data[:, 0], data[:, 1], c=label)
plt.show()
label_pred = dbscan(data,0.46,11)
print(label_pred)
# print(label_pred)
plt.title('DBSCAN')
plt.scatter(data[:, 0], data[:, 1], c=label_pred)
#图例
plt.show()
算法评价
优点:
- 不需要设置k值
- 可以发现任意形状的蔟
- 可以聚类的同时发现噪音点,即对噪音不敏感
- 对样本输入顺序不敢兴趣
缺点:
- 高维数据效果不理想
- 调参复杂,eps和Minpiont参数不好设置,无法预估。
K-means算法
算法原理
K-means算法是一种聚类算法,所谓聚类,即根据相似性原则,将具有较高相似度的数据对象划分至同一类簇,将具有较高相异度的数据对象划分至不同类簇。聚类与分类最大的区别在于,聚类过程为无监督过程,即待处理数据对象没有任何先验知识,而分类过程为有监督过程,即存在有先验知识的训练数据集。
k-means算法中的k代表类簇个数,means代表类簇内数据对象的均值(这种均值是一种对类簇中心的描述),因此,k-means算法又称为k-均值算法。k-means算法是一种基于划分的聚类算法,以距离作为数据对象间相似性度量的标准,即数据对象间的距离越小,则它们的相似性越高,则它们越有可能在同一个类簇。数据对象间距离的计算有很多种,k-means算法通常采用欧氏距离来计算数据对象间的距离。
算法流程
算法接受一个未标记的数据集,然后将数据聚类成不同的组。假设将数据分成k个组,方法为:
- 选择初始化的 $\mathrm{k}$ 个样本作为初始聚类中心 $a=a_1, a_2, \ldots a_k$ ;
- 针对数据集中每个样本 $x_i$ 计算它到 $\mathrm{k}$ 个聚类中心的距离并将其分到距离最小的聚类中心所对应 的类中;
- 针对每个类别 $a_j$ ,重新计算它的聚类中心 $a_j=\frac{1}{\left|c_i\right|} \sum_{x \in c_i} x$ (即属于该类的所有样本的质 心);
- 重复上面 23 两步操作,直到达到某个中止条件 (迭代次数、最小误差变化等)。
吴恩达视频的中的伪代码为
repeat {
for i= to m
# 计算每个样例属于的类
c(i) := index (from 1 to K) of cluster centroid closest to x(i)
for k = 1 to K
# 聚类中心的移动,重新计算该类的质心
u(k) := average (mean) of points assigned to cluster K
}
优化目标
这里的终止条件,我们用K-均值最小化问题,是要最小化所有的数据点与其所关联的聚类中心点之间的距离之和,因此K-均值的代价函数(畸变函数Distortion function) : $$ \begin{equation} J\left(c^{(1)}, \ldots, c^{(m)}, \mu_1, \ldots, \mu_K\right)=\frac{1}{m} \sum_{i=1}^m\left|X^{(i)}-\mu_{c^{(i)}}\right|^2 \end{equation} $$ 其中$\mu$代表与$x_i$最近的聚类中心点,$c^i$代表族类
优化目标就是找出使得代价函数最小的c和μ,即 $$ \begin{aligned} J\left(\underline{c^{(1)}, \ldots, c^{(m)}, \mu_1, \ldots, \mu_K}\right)=\frac{1}{m} \sum_{i=1}^m\left|x^{(i)}-\mu_{c^{(i)}}\right|^2\ \min _{\substack{c^{(1)}, \ldots, c^{(m)}\ \mu_1, \ldots, \mu_K}} J\left(c^{(1)}, \ldots, c^{(m)}, \mu_1, \ldots, \mu_K\right) \ & \end{aligned} $$
代码实现
加载数据
我们用Python的scikit-learn库中自带的鸢尾花数据集,并使用使用datasets.load_iris()载入,并用开头的两个维度进行画图
#加载数据
iris = load_iris()
#划分训练集和测试集
X_data, lable_data = iris.data, iris.target
def showData(X_data, lable_data):
#显示数据
plt.scatter(X_data[:, 0], X_data[:, 1], c=lable_data)
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.show()
数据处理
不同特征之间往往具有不同的量纲,由此所造成的数值间的差异可能很大,在涉及空间距离计算或梯度下降法等情况的时候不对其进行处理会影响到数据分析结果的准确性。为了消除特征之间的量纲和取值范围差异可能会造成的影响,需对数据进行标准化处理,也可以称为规范化处理。 在这里我们对数据集进行标准差标准化处理
MMS = MinMaxScaler().fit(X_data)
X_data = MMS.transform(X_data)
计算距离
初始化质心,我们选取k个样本作为初始的类的中心
def initCentroids(X_train, k):
#初始化质心
#随机选取k个样本作为初始质心
numSamples, dim = X_train.shape
centroids = np.zeros((k, dim))
for i in range(k):
index = int(np.random.uniform(0, numSamples))
centroids[i, :] = X_train[index, :]
return centroids
计算每个样本到类中心的距离,并选取其中欧拉距离最小的,并打上属于某个类的标记
def OulerDistance(vec1, vec2):
#欧拉距离
#计算两个向量的欧拉距离 :math:`d = \sqrt{\sum_{i=1}^n (x_i - y_i)^2}`
#vec1-vec2表示两个向量的对应元素的差
return np.sqrt(np.sum(np.square(vec1 - vec2)))
def minDistance(X_train, centroids):
#计算每个样本到质心的距离
#返回每个样本所属的簇
numSamples = X_train.shape[0]
clusterDict = dict()
k=centroids.shape[0]
for flower in X_train:
vec1=flower
flag = -1
minDist = float('inf')#无穷大
for i in range(k):
vec2=centroids[i]
distance = OulerDistance(vec1, vec2)
if distance < minDist:
minDist = distance
flag = i#标记为第i个簇
if flag not in clusterDict.keys():
clusterDict[flag] = []
clusterDict[flag].append(flower)#将该样本加入到第i个簇中
return clusterDict#返回每个样本所属的簇
求两个向量的欧拉距离: $$ d = \sqrt{\sum_{i=1}^n (x_i - y_i)^2} $$ 获取更新新的聚类中心
def getCentroids(clusterDict):
#计算新的质心
#返回新的质心
centroids = np.zeros((len(clusterDict),len(clusterDict[0][0])))
for i, cluster in clusterDict.items():
cluster = np.array(cluster)
centroids[i, :] = np.mean(cluster, axis=0)
return centroids
def getVaration(clusterDict, centroids):
#计算簇内误差平方和
#返回簇内误差平方和
variation = 0.0
for i, cluster in clusterDict.items():
variation += np.sum(np.square(cluster - centroids[i, :]))
return variation
针对每个类别 $a_j$,重新计算它的聚类中心 $a_j=\frac{1}{\left|c_i\right|} \sum_{x \in c_i} x$ (即属于该类的所有样本的质心);
寻找最小mean
new_variation = getVaration(clusterDict, centroids)
#显示图形
old_variation = 1
while abs(new_variation - old_variation) > 0.0001:
old_variation = new_variation
centroids = getCentroids(clusterDict)
clusterDict = minDistance(X_data, centroids)
new_variation = getVaration(clusterDict, centroids)
可视化模型
根据前两个维度画出散点图
def showCluster(centroids, clusterDict):
#获取聚类标签
labels0 = np.array(clusterDict[0])
labels1 = np.array(clusterDict[1])
labels2 = np.array(clusterDict[2])
#绘制样本点
plt.scatter(labels0[:, 0], labels0[:, 1], marker='x', color='r', label='label0')
plt.scatter(labels1[:, 0], labels1[:, 1], marker='o', color='g', label='label1')
plt.scatter(labels2[:, 0], labels2[:, 1], marker='*', color='b', label='label2')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
#绘制质心
plt.scatter(centroids[:, 0], centroids[:, 1], marker='+', color='black', label='centroids', s=300)
plt.legend(loc='upper right')
plt.title('the result of K-means')
plt.show()
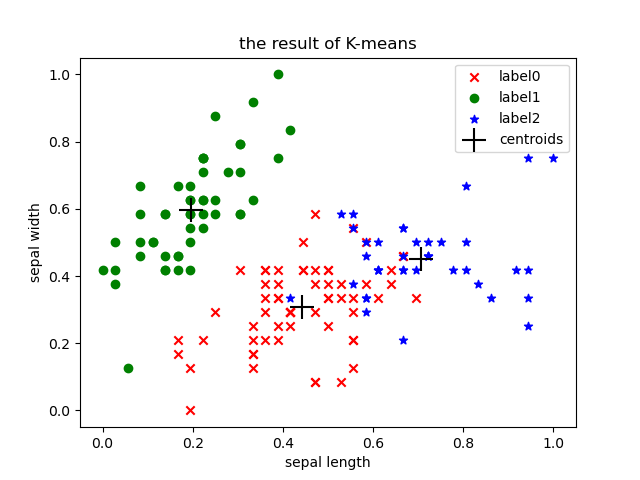
评估K-means模型
print('轮廓系数为:', silhouette_score(X_data, lable_data, metric='euclidean'))

为了作对比这里直接调用sklearn库进行模拟,方便我们分析,对比
在这里我们获取轮廓系数score是所有样本的轮廓系数均值,如果要获取每个样本的轮廓系数应当使用silhouette_samples。这里是针对超参数k(n_cluster),所以采用轮廓系数均值进行评估。
from sklearn.metrics import silhouette_score
from sklearn.preprocessing import MinMaxScaler
from sklearn.cluster import KMeans
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
iris_data = load_iris()
x = iris_data.data
y = iris_data.target
MMS = MinMaxScaler().fit(x)
data = MMS.transform(x)
#构建KMeans模型训练数据
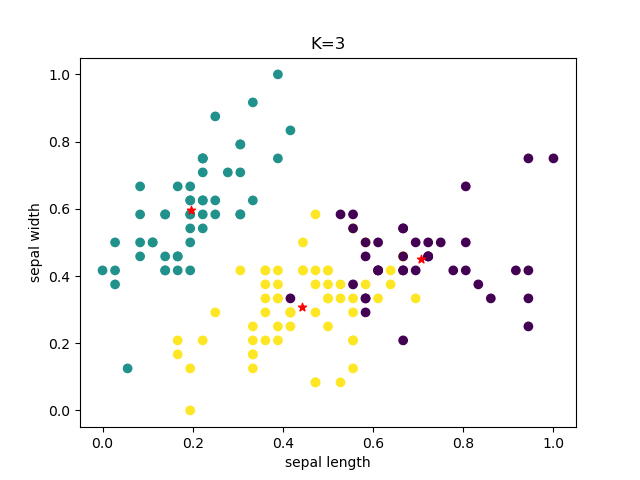
cluster = KMeans(n_clusters=3,random_state=123).fit(data)
#获取聚类结果
y_pred = cluster.labels_
#获取聚类中心
centers = cluster.cluster_centers_
#获取聚类的内部误差平方和
inertia = cluster.inertia_
#计算轮廓系数
print('轮廓系数为:', silhouette_score(data, y_pred, metric='euclidean'))
#显示聚类结果
plt.scatter(data[:, 0], data[:, 1], c=y_pred)
plt.scatter(centers[:, 0], centers[:, 1], c='red', marker='*')
plt.show()
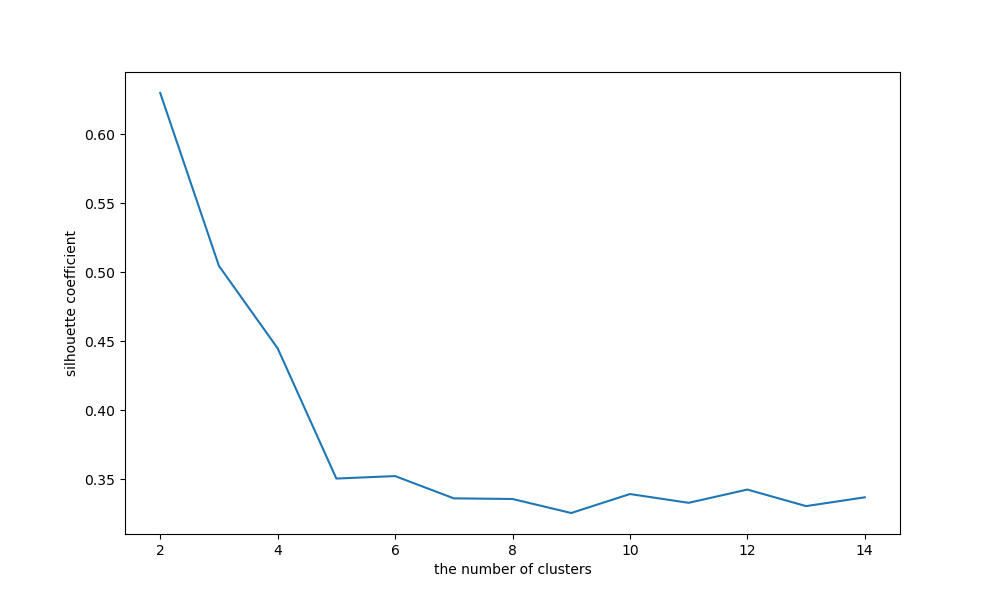
silhouetteScore = []
for i in range(2,15):
# 构建并训练模型
kmeans = KMeans(n_clusters=i,random_state=123).fit(data)
score = silhouette_score(data,kmeans.labels_)
silhouetteScore.append(score)
plt.figure(figsize=(10,6))
plt.plot(range(2,15),silhouetteScore,linewidth=1.5,linestyle='-')
plt.xlabel('the number of clusters')
plt.ylabel('silhouette coefficient')
plt.show()
可以看到聚类数目为2、3和4、5的时候,图形的畸变程度最大。本身数据集就是关于3种鸢尾花的,侧面说明了聚类为3的时候效果较好,且用库的和实现的效果一致
完整代码
from sklearn.datasets import load_iris
from sklearn.preprocessing import MinMaxScaler
from sklearn.manifold import TSNE
from sklearn.metrics import silhouette_score
import numpy as np
import matplotlib.pyplot as plt
def showData(X_data, lable_data):
#显示数据
plt.scatter(X_data[:, 0], X_data[:, 1], c=lable_data)
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.title('the original data')
plt.show()
def showCluster(centroids, clusterDict):
#获取聚类标签
labels0 = np.array(clusterDict[0])
labels1 = np.array(clusterDict[1])
labels2 = np.array(clusterDict[2])
#绘制样本点
plt.scatter(labels0[:, 0], labels0[:, 1], marker='x', color='r', label='label0')
plt.scatter(labels1[:, 0], labels1[:, 1], marker='o', color='g', label='label1')
plt.scatter(labels2[:, 0], labels2[:, 1], marker='*', color='b', label='label2')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
#绘制质心
plt.scatter(centroids[:, 0], centroids[:, 1], marker='+', color='black', label='centroids', s=300)
plt.legend(loc='upper right')
plt.title('the result of K-means')
plt.show()
def OulerDistance(vec1, vec2):
#欧拉距离
#计算两个向量的欧拉距离 :math:`d = \sqrt{\sum_{i=1}^n (x_i - y_i)^2}`
#vec1-vec2表示两个向量的对应元素的差
return np.sqrt(np.sum(np.square(vec1 - vec2)))
def initCentroids(X_train, k):
#初始化质心
#随机选取k个样本作为初始质心
numSamples, dim = X_train.shape
centroids = np.zeros((k, dim))
for i in range(k):
index = int(np.random.uniform(0, numSamples))
centroids[i, :] = X_train[index, :]
return centroids
def minDistance(X_train, centroids):
#计算每个样本到质心的距离
#返回每个样本所属的簇
numSamples = X_train.shape[0]
clusterDict = dict()
k=centroids.shape[0]
for flower in X_train:
vec1=flower
flag = -1
minDist = float('inf')#无穷大
for i in range(k):
vec2=centroids[i]
distance = OulerDistance(vec1, vec2)
if distance < minDist:
minDist = distance
flag = i#标记为第i个簇
if flag not in clusterDict.keys():
clusterDict[flag] = []
clusterDict[flag].append(flower)#将该样本加入到第i个簇中
return clusterDict#返回每个样本所属的簇
def getCentroids(clusterDict):
#计算新的质心
#返回新的质心
centroids = np.zeros((len(clusterDict),len(clusterDict[0][0])))
for i, cluster in clusterDict.items():
cluster = np.array(cluster)
centroids[i, :] = np.mean(cluster, axis=0)
return centroids
def getVaration(clusterDict, centroids):
#计算簇内误差平方和
#返回簇内误差平方和
variation = 0.0
for i, cluster in clusterDict.items():
variation += np.sum(np.square(cluster - centroids[i, :]))
return variation
def Kmeans():
#加载数据
iris = load_iris()
#划分训练集和测试集
X_data, lable_data = iris.data, iris.target
#
showData(X_data, lable_data)
#数据归一化
MMS = MinMaxScaler().fit(X_data)
X_data = MMS.transform(X_data)
#初始化质心
k = 3
centroids = initCentroids(X_data, k)
#计算每个样本到质心的距离
clusterDict = minDistance(X_data, centroids)
#计算新的质心
centroids = getCentroids(clusterDict)
#计算簇内误差平方和
new_variation = getVaration(clusterDict, centroids)
#显示图形
old_variation = 1
while abs(new_variation - old_variation) > 0.0001:
old_variation = new_variation
centroids = getCentroids(clusterDict)
clusterDict = minDistance(X_data, centroids)
new_variation = getVaration(clusterDict, centroids)
showCluster(centroids, clusterDict)
#计算轮廓系数
print('轮廓系数为:', silhouette_score(X_data, lable_data, metric='euclidean'))
if __name__ == '__main__':
Kmeans()
算法评价
优点:
1.是解决聚类问题的一种经典算法,简单、快速
2.对处理大数据集,该算法保持可伸缩性和高效率
3.当结果簇是密集的,它的效果较好
缺点
1.在簇的平均值可被定义的情况下才能使用,可能不适用于某些应用
2.必须事先给出k(要生成的簇的数目),而且对初值敏感,对于不同的初始值,可能会导致不同结果。
3.不适合于发现非凸形状的簇或者大小差别很大的簇
4.对躁声和孤立点数据敏感
参考文献
Supervised Machine Learning: Regression and Classification